
당신은 주제를 찾고 있습니까 “파이썬 감성 분석 – 이것이 데이터 분석이다 (파이썬 편) – 17. 4장 감성 분석이란“? 다음 카테고리의 웹사이트 th.taphoamini.com 에서 귀하의 모든 질문에 답변해 드립니다: th.taphoamini.com/wiki. 바로 아래에서 답을 찾을 수 있습니다. 작성자 야마래 이(가) 작성한 기사에는 조회수 1,165회 및 좋아요 12개 개의 좋아요가 있습니다.
Table of Contents
파이썬 감성 분석 주제에 대한 동영상 보기
여기에서 이 주제에 대한 비디오를 시청하십시오. 주의 깊게 살펴보고 읽고 있는 내용에 대한 피드백을 제공하세요!
d여기에서 이것이 데이터 분석이다 (파이썬 편) – 17. 4장 감성 분석이란 – 파이썬 감성 분석 주제에 대한 세부정보를 참조하세요
이것이 데이터 분석이다 (파이썬 편) 4장 감성 분석에 대한 영상입니다.
본 영상은 이 채널의 스트리밍 강의 영상의 편집본입니다.
최종 편집된 영상은 아래 주소에서 보실 수 있습니다.
https://www.youtube.com/user/HanbitMedia93
파이썬 감성 분석 주제에 대한 자세한 내용은 여기를 참조하세요.
6) 네이버 영화 리뷰 감성 분류하기(Naver Movie Review …
6) 네이버 영화 리뷰 감성 분류하기(Naver Movie Review Sentiment Analysis). 이번에 사용할 데이터는 네이버 영화 리뷰 데이터입니다. 총 200,000개 리뷰로 구성된 …
Source: wikidocs.net
Date Published: 4/2/2021
View: 128
[python/NLP] 감정분류(한국어)- 리뷰데이터 학습, 평가, 예측까지
그 후 DATA 라는 폴더를 만들어 그 안에 파일들이 위치하도록 해줍니다. 데이터 분석하기. 감정분류에 사용할 데이터가 어떻게 이루어져있는지 살펴보도록 …
Source: wonhwa.tistory.com
Date Published: 9/19/2021
View: 8646
[Python] 소셜 데이터의 감성 예측 – velog
학습 내용 · 모듈 설치 · 파이썬 3.8이하 (중요) · 핵심 개념 · 단어 표현의 카테고리화 · 카운트 기반 벡터화 · TF-IDF 기반 벡터화 · 감성 분석(오피니언 …
Source: velog.io
Date Published: 9/25/2022
View: 4385
【실습】 Python >> Text Mining — 감성 분류 분석 (호텔 리뷰 …
감성 분류 예측 모델 도출 (Logistic Regression); 2. … 【실습】 Python >> Text Mining — 감성 분류 분석 (호텔 리뷰 데이터).
Source: hyemin-kim.github.io
Date Published: 10/18/2022
View: 2942
감정 분석 Sentiment Analysis | 파이썬 감성 분석 최신
이에 대한 추가 정보 파이썬 감성 분석 주제에 대해서는 다음 문서를 참조하십시오. 아이디어가 있으면 기사 아래에 댓글을 달거나 주제에 대한 다른 관련 …
Source: ko.nataviguides.com
Date Published: 1/30/2021
View: 9479
감정 분석(Sentiment Analysis) – Google Colab
파이썬으로 감정 분석하는 방법은 크게 두 가지로 구분. 감정 어휘 사전을 이용한 감정 상태 분류. 미리 분류해둔 감정어 사전을 통해 분석하고자 하는 텍스트의 단어 …
Source: colab.research.google.com
Date Published: 3/29/2021
View: 1890
[파이썬] 네이버 클로바 Sentiment 문장 텍스트 감정 분석
[파이썬] 네이버 클로바 Sentiment 문장 텍스트 감정 분석 … 바빠서 시간이 부족하거나 파이썬 코딩이 처음인 사람들이 많다. 누구나 손쉽게 코딩을 …Source: dataanalytics.tistory.com
Date Published: 10/16/2021
View: 2594
감성 분석 – 데이터 사이언스 스쿨
감성 분석¶. 앞에서 공부한 나이브 베이즈 분류 모형을 이용하여 문서에 대한 감성 분석(sentiment analysis)를 해보자. 감성 분석이란 문서에 대해 좋다(positive) …
Source: datascienceschool.net
Date Published: 12/25/2022
View: 1638
[Python] 뉴스 감성지수 분류 모델 – sieon
Test Set의 정확도 역시 0.91로 높은 성능을 보이고 있습니다. 이후 이 모델을 웹 서버에 Deploy 하여 네이버 News API를 통해 수집한 뉴스들을 분석하는 …
Source: sieon-dev.tistory.com
Date Published: 11/27/2022
View: 8495
한국어 감성분석, 감성 기반 추천 시스템 제작 – 시그모이드
3달 여간의 교육을 받으며 파이썬부터 시작해서 ML, DL의 기초 OpenCV를 간단하게 다뤄보았다. 배운 것들을 토대로 모델을 만드는 프로젝트를 진행 …
Source: sig413.tistory.com
Date Published: 3/19/2022
View: 5407
주제와 관련된 이미지 파이썬 감성 분석
주제와 관련된 더 많은 사진을 참조하십시오 이것이 데이터 분석이다 (파이썬 편) – 17. 4장 감성 분석이란. 댓글에서 더 많은 관련 이미지를 보거나 필요한 경우 더 많은 관련 기사를 볼 수 있습니다.
주제에 대한 기사 평가 파이썬 감성 분석
- Author: 야마래
- Views: 조회수 1,165회
- Likes: 좋아요 12개
- Date Published: 2020. 3. 26.
- Video Url link: https://www.youtube.com/watch?v=R1hA5qVUnhg
6) 네이버 영화 리뷰 감성 분류하기(Naver Movie Review Sentiment Analysis)
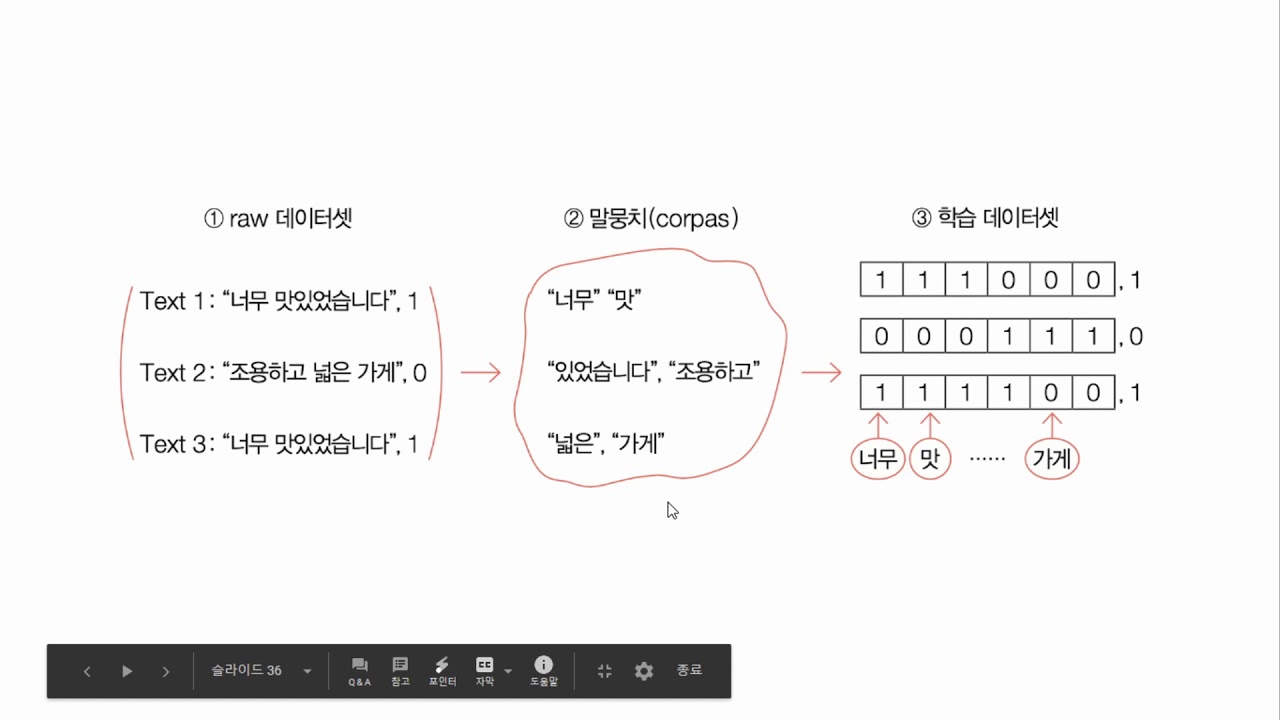
이번에 사용할 데이터는 네이버 영화 리뷰 데이터입니다. 총 200,000개 리뷰로 구성된 데이터로 영화 리뷰에 대한 텍스트와 해당 리뷰가 긍정인 경우 1, 부정인 경우 0을 표시한 레이블로 구성되어져 있습니다. 해당 데이터를 다운로드 받아 감성 분류를 수행하는 모델을 만들어보겠습니다.
1. 네이버 영화 리뷰 데이터에 대한 이해와 전처리
데이터 다운로드 링크 : https://github.com/e9t/nsmc/
import pandas as pd import numpy as np import matplotlib.pyplot as plt import re import urllib.request from konlpy.tag import Okt from tqdm import tqdm from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences
1) 데이터 로드하기
위 링크로부터 훈련 데이터에 해당하는 ratings_train.txt와 테스트 데이터에 해당하는 ratings_test.txt를 다운로드합니다.
urllib.request.urlretrieve(“https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt”, filename=”ratings_train.txt”) urllib.request.urlretrieve(“https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt”, filename=”ratings_test.txt”)
pandas를 이용하여 훈련 데이터는 train_data에 테스트 데이터는 test_data에 저장합니다.
train_data = pd.read_table(‘ratings_train.txt’) test_data = pd.read_table(‘ratings_test.txt’)
train_data에 존재하는 영화 리뷰의 개수를 확인해봅시다.
print(‘훈련용 리뷰 개수 :’,len(train_data)) # 훈련용 리뷰 개수 출력
훈련용 리뷰 개수 : 150000
train_data는 총 150,000개의 리뷰가 존재합니다. 상위 5개의 샘플을 출력해봅시다.
train_data[:5] # 상위 5개 출력
해당 데이터는 id, document, label 총 3개의 열로 구성되어져 있습니다. id는 감성 분류를 수행하는데 도움이 되지 않으므로 앞으로 무시합니다. 결국 이 모델은 리뷰 내용을 담고있는 document와 해당 리뷰가 긍정(1), 부정(0)인지를 나타내는 label 두 개의 열을 학습하는 모델이 되어야 합니다.
또한 단지 상위 5개의 샘플만 출력해보았지만 한국어 데이터와 영어 데이터의 차이를 확인할 수 있습니다. 예를 들어, 인덱스 2번 샘플은 띄어쓰기를 하지 않아도 글을 쉽게 이해할 수 있는 한국어의 특성으로 인해 띄어쓰기가 되어있지 않습니다. test_data의 리뷰 개수와 상위 5개의 샘플을 확인해봅시다.
print(‘테스트용 리뷰 개수 :’,len(test_data)) # 테스트용 리뷰 개수 출력
테스트용 리뷰 개수 : 50000
test_data는 총 50,000개의 영화 리뷰가 존재합니다. 상위 5개의 샘플을 출력해봅시다.
test_data[:5]
test_data도 train_data와 동일한 형식으로 id, document, label 3개의 열로 구성되어져 있습니다.
2) 데이터 정제하기
train_data의 데이터 중복 유무를 확인합니다.
# document 열과 label 열의 중복을 제외한 값의 개수 train_data[‘document’].nunique(), train_data[‘label’].nunique()
(146182, 2)
총 150,000개의 샘플이 존재하는데 document열에서 중복을 제거한 샘플의 개수가 146,182개라는 것은 약 4,000개의 중복 샘플이 존재한다는 의미입니다. label 열은 0 또는 1의 두 가지 값만을 가지므로 2가 출력됩니다. 중복 샘플을 제거합니다.
# document 열의 중복 제거 train_data.drop_duplicates(subset=[‘document’], inplace=True)
중복 샘플을 제거하였습니다. 중복이 제거되었는지 전체 샘플 수를 확인합니다.
print(‘총 샘플의 수 :’,len(train_data))
총 샘플의 수 : 146183
중복 샘플이 제거되었습니다. train_data에서 해당 리뷰의 긍, 부정 유무가 기재되어있는 레이블(label) 값의 분포를 보겠습니다.
train_data[‘label’].value_counts().plot(kind = ‘bar’)
앞서 확인하였듯이 약 146,000개의 영화 리뷰 샘플이 존재하는데 그래프 상으로 긍정과 부정 둘 다 약 72,000개의 샘플이 존재하여 레이블의 분포가 균일한 것처럼 보입니다. 정확하게 몇 개인지 확인해봅시다.
print(train_data.groupby(‘label’).size().reset_index(name = ‘count’))
label count 0 0 73342 1 1 72841
레이블이 0인 리뷰가 근소하게 많습니다. 리뷰 중에 Null 값을 가진 샘플이 있는지 확인합니다.
print(train_data.isnull().values.any())
True
True가 나왔다면 데이터 중에 Null 값을 가진 샘플이 존재한다는 의미입니다. 어떤 열에 존재하는지 확인해봅시다.
print(train_data.isnull().sum())
id 0 document 1 label 0 dtype: int64
리뷰가 적혀있는 document 열에서 Null 값을 가진 샘플이 총 1개가 존재한다고 합니다. 그렇다면 document 열에서 Null 값이 존재한다는 것을 조건으로 Null 값을 가진 샘플이 어느 인덱스의 위치에 존재하는지 한 번 출력해봅시다.
train_data.loc[train_data.document.isnull()]
출력 결과는 위와 같습니다. Null 값을 가진 샘플을 제거하겠습니다.
train_data = train_data.dropna(how = ‘any’) # Null 값이 존재하는 행 제거 print(train_data.isnull().values.any()) # Null 값이 존재하는지 확인
False
Null 값을 가진 샘플이 제거되었습니다. 다시 샘플의 개수를 출력하여 1개의 샘플이 제거되었는지 확인해봅시다.
print(len(train_data))
146182
데이터의 전처리를 수행해보겠습니다. 위의 train_data와 test_data에서 온점(.)이나 ?와 같은 각종 특수문자가 사용된 것을 확인했습니다. train_data로부터 한글만 남기고 제거하기 위해서 정규 표현식을 사용해보겠습니다.
우선 영어를 예시로 정규 표현식을 설명해보겠습니다. 영어의 알파벳들을 나타내는 정규 표현식은 [a-zA-Z]입니다. 이 정규 표현식은 영어의 소문자와 대문자들을 모두 포함하고 있는 정규 표현식으로 이를 응용하면 영어에 속하지 않는 구두점이나 특수문자를 제거할 수 있습니다. 예를 들어 알파벳과 공백을 제외하고 모두 제거하는 전처리를 수행하는 예제는 다음과 같습니다.
#알파벳과 공백을 제외하고 모두 제거 eng_text = ‘do!!! you expect… people~ to~ read~ the FAQ, etc. and actually accept hard~! atheism?@@’ print(re.sub(r'[^a-zA-Z ]’, ”, eng_text))
‘do you expect people to read the FAQ etc and actually accept hard atheism’
위와 같은 원리를 한국어 데이터에 적용하고 싶다면, 우선 한글을 범위 지정할 수 있는 정규 표현식을 찾아내면 되겠습니다. 우선 자음과 모음에 대한 범위를 지정해보겠습니다. 일반적으로 자음의 범위는 ㄱ ~ ㅎ, 모음의 범위는 ㅏ ~ ㅣ와 같이 지정할 수 있습니다. 해당 범위 내에 어떤 자음과 모음이 속하는지 알고 싶다면 아래의 링크를 참고하시기 바랍니다.
링크 : https://www.unicode.org/charts/PDF/U3130.pdf
ㄱ ~ ㅎ: 3131 ~ 314E
ㅏ ~ ㅣ: 314F ~ 3163
완성형 한글의 범위는 가 ~ 힣과 같이 사용합니다. 해당 범위 내에 포함된 음절들은 아래의 링크에서 확인할 수 있습니다.
링크 : https://www.unicode.org/charts/PDF/UAC00.pdf
위 범위 지정을 모두 반영하여 train_data에 한글과 공백을 제외하고 모두 제거하는 정규 표현식을 수행해봅시다.
# 한글과 공백을 제외하고 모두 제거 train_data[‘document’] = train_data[‘document’].str.replace(“[^ㄱ-ㅎㅏ-ㅣ가-힣 ]”,””) train_data[:5]
상위 5개의 샘플을 다시 출력해보았는데, 정규 표현식을 수행하자 기존의 공백. 즉, 띄어쓰기는 유지되면서 온점과 같은 구두점 등은 제거되었습니다. 사실 네이버 영화 리뷰는 한글이 아니더라도 영어, 숫자, 특수문자로도 리뷰를 업로드할 수 있습니다. 다시 말해 기존에 한글이 없는 리뷰였다면 더 이상 아무런 값도 없는 빈(empty) 값이 되었을 것입니다. train_data에 공백(whitespace)만 있거나 빈 값을 가진 행이 있다면 Null 값으로 변경하도록 하고, Null 값이 존재하는지 확인해보겠습니다.
train_data[‘document’] = train_data[‘document’].str.replace(‘^ +’, “”) # white space 데이터를 empty value로 변경 train_data[‘document’].replace(”, np.nan, inplace=True) print(train_data.isnull().sum())
id 0 document 789 label 0 dtype: int64
Null 값이 789개나 새로 생겼습니다. Null 값이 있는 행을 5개만 출력해볼까요?
train_data.loc[train_data.document.isnull()][:5]
Null 샘플들은 레이블이 긍정일 수도 있고, 부정일 수도 있습니다. 아무런 의미도 없는 데이터므로 제거해줍니다.
train_data = train_data.dropna(how = ‘any’) print(len(train_data))
145393
샘플 개수가 또 다시 줄어서 145,393개가 남았습니다. 테스트 데이터에 앞서 진행한 전처리 과정을 동일하게 진행합니다.
test_data.drop_duplicates(subset = [‘document’], inplace=True) # document 열에서 중복인 내용이 있다면 중복 제거 test_data[‘document’] = test_data[‘document’].str.replace(“[^ㄱ-ㅎㅏ-ㅣ가-힣 ]”,””) # 정규 표현식 수행 test_data[‘document’] = test_data[‘document’].str.replace(‘^ +’, “”) # 공백은 empty 값으로 변경 test_data[‘document’].replace(”, np.nan, inplace=True) # 공백은 Null 값으로 변경 test_data = test_data.dropna(how=’any’) # Null 값 제거 print(‘전처리 후 테스트용 샘플의 개수 :’,len(test_data))
전처리 후 테스트용 샘플의 개수 : 48852
3) 토큰화
토큰화를 진행해봅시다. 토큰화 과정에서 불용어를 제거하겠습니다. 불용어는 정의하기 나름인데, 한국어의 조사, 접속사 등의 보편적인 불용어를 사용할 수도 있겠지만 결국 풀고자 하는 문제의 데이터를 지속 검토하면서 계속해서 추가하는 경우 또한 많습니다. 실제 현업인 상황이라면 일반적으로 아래의 불용어보다 더 많은 불용어를 사용할 수 있습니다.
stopwords = [‘의’,’가’,’이’,’은’,’들’,’는’,’좀’,’잘’,’걍’,’과’,’도’,’를’,’으로’,’자’,’에’,’와’,’한’,’하다’]
여기서는 위 정도로만 불용어를 정의하고, 토큰화를 위한 형태소 분석기는 KoNLPy의 Okt를 사용합니다. Okt를 복습해봅시다.
okt = Okt() okt.morphs(‘와 이런 것도 영화라고 차라리 뮤직비디오를 만드는 게 나을 뻔’, stem = True)
[‘오다’, ‘이렇다’, ‘것’, ‘도’, ‘영화’, ‘라고’, ‘차라리’, ‘뮤직비디오’, ‘를’, ‘만들다’, ‘게’, ‘나다’, ‘뻔’]Okt는 위와 같이 KoNLPy에서 제공하는 형태소 분석기입니다. 한국어을 토큰화할 때는 영어처럼 띄어쓰기 기준으로 토큰화를 하는 것이 아니라, 주로 형태소 분석기를 사용한다고 언급한 바 있습니다. stem = True를 사용하면 일정 수준의 정규화를 수행해주는데, 예를 들어 위의 예제의 결과를 보면 ‘이런’이 ‘이렇다’로 변환되었고 ‘만드는’이 ‘만들다’로 변환된 것을 알 수 있습니다. train_data에 형태소 분석기를 사용하여 토큰화를 하면서 불용어를 제거하여 X_train에 저장합니다.
X_train = [] for sentence in tqdm(train_data[‘document’]): tokenized_sentence = okt.morphs(sentence, stem=True) # 토큰화 stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords] # 불용어 제거 X_train.append(stopwords_removed_sentence)
상위 3개의 샘플만 출력하여 결과를 확인해봅시다.
print(X_train[:3])
[[‘아’, ‘더빙’, ‘진짜’, ‘짜증나다’, ‘목소리’], [‘흠’, ‘포스터’, ‘보고’, ‘초딩’, ‘영화’, ‘줄’, ‘오버’, ‘연기’, ‘조차’, ‘가볍다’, ‘않다’], [‘너’, ‘무재’, ‘밓었’, ‘다그’, ‘래서’, ‘보다’, ‘추천’, ‘다’]]형태소 토큰화가 진행된 것을 볼 수 있습니다. 테스트 데이터에 대해서도 동일하게 토큰화를 해줍니다.
X_test = [] for sentence in tqdm(test_data[‘document’]): tokenized_sentence = okt.morphs(sentence, stem=True) # 토큰화 stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords] # 불용어 제거 X_test.append(stopwords_removed_sentence)
지금까지 훈련 데이터와 테스트 데이터에 대해서 텍스트 전처리를 진행해보았습니다.
4) 정수 인코딩
기계가 텍스트를 숫자로 처리할 수 있도록 훈련 데이터와 테스트 데이터에 정수 인코딩을 수행해야 합니다. 우선, 훈련 데이터에 대해서 단어 집합(vocaburary)을 만들어봅시다.
tokenizer = Tokenizer() tokenizer.fit_on_texts(X_train)
단어 집합이 생성되는 동시에 각 단어에 고유한 정수가 부여되었습니다. 이는 tokenizer.word_index를 출력하여 확인 가능합니다.
print(tokenizer.word_index)
{‘영화’: 1, ‘보다’: 2, ‘을’: 3, ‘없다’: 4, ‘이다’: 5, ‘있다’: 6, ‘좋다’: 7, … 중략 … ‘디케이드’: 43751, ‘수간’: 43752}
단어가 43,000개가 넘게 존재합니다. 각 정수는 전체 훈련 데이터에서 등장 빈도수가 높은 순서대로 부여되었기 때문에, 높은 정수가 부여된 단어들은 등장 빈도수가 매우 낮다는 것을 의미합니다. 여기서는 빈도수가 낮은 단어들은 자연어 처리에서 배제하고자 합니다. 등장 빈도수가 3회 미만인 단어들이 이 데이터에서 얼만큼의 비중을 차지하는지 확인해봅시다.
threshold = 3 total_cnt = len(tokenizer.word_index) # 단어의 수 rare_cnt = 0 # 등장 빈도수가 threshold보다 작은 단어의 개수를 카운트 total_freq = 0 # 훈련 데이터의 전체 단어 빈도수 총 합 rare_freq = 0 # 등장 빈도수가 threshold보다 작은 단어의 등장 빈도수의 총 합 # 단어와 빈도수의 쌍(pair)을 key와 value로 받는다. for key, value in tokenizer.word_counts.items(): total_freq = total_freq + value # 단어의 등장 빈도수가 threshold보다 작으면 if(value < threshold): rare_cnt = rare_cnt + 1 rare_freq = rare_freq + value print('단어 집합(vocabulary)의 크기 :',total_cnt) print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt)) print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt)*100) print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq)*100) 단어 집합(vocabulary)의 크기 : 43752 등장 빈도가 2번 이하인 희귀 단어의 수: 24337 단어 집합에서 희귀 단어의 비율: 55.62488571950996 전체 등장 빈도에서 희귀 단어 등장 빈도 비율: 1.8715872104872904 등장 빈도가 threshold 값인 3회 미만. 즉, 2회 이하인 단어들은 단어 집합에서 무려 절반 이상을 차지합니다. 하지만, 실제로 훈련 데이터에서 등장 빈도로 차지하는 비중은 상대적으로 매우 적은 수치인 1.87%밖에 되지 않습니다. 아무래도 등장 빈도가 2회 이하인 단어들은 자연어 처리에서 별로 중요하지 않을 듯 합니다. 그래서 이 단어들은 정수 인코딩 과정에서 배제시키겠습니다. 등장 빈도수가 2이하인 단어들의 수를 제외한 단어의 개수를 단어 집합의 최대 크기로 제한하겠습니다. # 전체 단어 개수 중 빈도수 2이하인 단어는 제거. # 0번 패딩 토큰을 고려하여 + 1 vocab_size = total_cnt - rare_cnt + 1 print('단어 집합의 크기 :',vocab_size) 단어 집합의 크기 : 19416 단어 집합의 크기는 19,416개입니다. 이를 케라스 토크나이저의 인자로 넘겨주고 텍스트 시퀀스를 정수 시퀀스로 변환합니다. tokenizer = Tokenizer(vocab_size) tokenizer.fit_on_texts(X_train) X_train = tokenizer.texts_to_sequences(X_train) X_test = tokenizer.texts_to_sequences(X_test) 정수 인코딩이 진행되었는지 확인하고자 X_train에 대해서 상위 3개의 샘플만 출력합니다. print(X_train[:3]) [[50, 454, 16, 260, 659], [933, 457, 41, 602, 1, 214, 1449, 24, 961, 675, 19], [386, 2444, 2315, 5671, 2, 222, 9]] 각 샘플 내의 단어들은 각 단어에 대한 정수로 변환된 것을 확인할 수 있습니다. 단어의 개수는 19,416개로 제한되었으므로 0번 단어 ~ 19,415번 단어까지만 사용 중입니다. 0번 단어는 패딩을 위한 토큰임을 상기합시다. train_data에서 y_train과 y_test를 별도로 저장해줍니다. y_train = np.array(train_data['label']) y_test = np.array(test_data['label']) 5) 빈 샘플(empty samples) 제거 전체 데이터에서 빈도수가 낮은 단어가 삭제되었다는 것은 빈도수가 낮은 단어만으로 구성되었던 샘플들은 빈(empty) 샘플이 되었다는 것을 의미합니다. 빈 샘플들은 어떤 레이블이 붙어있던 의미가 없으므로 빈 샘플들을 제거해주는 작업을 하겠습니다. 각 샘플들의 길이를 확인해서 길이가 0인 샘플들의 인덱스를 받아오겠습니다. drop_train = [index for index, sentence in enumerate(X_train) if len(sentence) < 1] drop_train에는 X_train으로부터 얻은 빈 샘플들의 인덱스가 저장됩니다. 앞서 훈련 데이터(X_train, y_train)의 샘플 개수는 145,791개임을 확인했었습니다. 그렇다면 빈 샘플들을 제거한 후의 샘플 개수는 몇 개일까요? # 빈 샘플들을 제거 X_train = np.delete(X_train, drop_train, axis=0) y_train = np.delete(y_train, drop_train, axis=0) print(len(X_train)) print(len(y_train)) 145162 145162 145,162개로 샘플의 수가 줄어든 것을 확인할 수 있습니다. 6) 패딩 서로 다른 길이의 샘플들의 길이를 동일하게 맞춰주는 패딩 작업을 진행해보겠습니다. 전체 데이터에서 가장 길이가 긴 리뷰와 전체 데이터의 길이 분포를 알아보겠습니다. print('리뷰의 최대 길이 :',max(len(review) for review in X_train)) print('리뷰의 평균 길이 :',sum(map(len, X_train))/len(X_train)) plt.hist([len(review) for review in X_train], bins=50) plt.xlabel('length of samples') plt.ylabel('number of samples') plt.show() 리뷰의 최대 길이 : 69 리뷰의 평균 길이 : 10.812485361182679 가장 긴 리뷰의 길이는 69이며, 그래프를 봤을 때 전체 데이터의 길이 분포는 대체적으로 약 11내외의 길이를 가지는 것을 볼 수 있습니다. 모델이 처리할 수 있도록 X_train과 X_test의 모든 샘플의 길이를 특정 길이로 동일하게 맞춰줄 필요가 있습니다. 특정 길이 변수를 max_len으로 정합니다. 대부분의 리뷰가 내용이 잘리지 않도록 할 수 있는 최적의 max_len의 값은 몇일까요? 전체 샘플 중 길이가 max_len 이하인 샘플의 비율이 몇 %인지 확인하는 함수를 만듭니다. def below_threshold_len(max_len, nested_list): count = 0 for sentence in nested_list: if(len(sentence) <= max_len): count = count + 1 print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s'%(max_len, (count / len(nested_list))*100)) 위의 분포 그래프를 봤을 때, max_len = 30이 적당할 것 같습니다. 이 값이 얼마나 많은 리뷰 길이를 커버하는지 확인해봅시다. max_len = 30 below_threshold_len(max_len, X_train) 전체 샘플 중 길이가 30 이하인 샘플의 비율: 94.31944999380003 전체 훈련 데이터 중 약 94%의 리뷰가 30이하의 길이를 가지는 것을 확인했습니다. 모든 샘플의 길이를 30으로 맞추겠습니다. X_train = pad_sequences(X_train, maxlen=max_len) X_test = pad_sequences(X_test, maxlen=max_len) 2. LSTM으로 네이버 영화 리뷰 감성 분류하기 하이퍼파라미터인 임베딩 벡터의 차원은 100, 은닉 상태의 크기는 128입니다. 모델은 다 대 일 구조의 LSTM을 사용합니다. 해당 모델은 마지막 시점에서 두 개의 선택지 중 하나를 예측하는 이진 분류 문제를 수행하는 모델입니다. 이진 분류 문제의 경우, 출력층에 로지스틱 회귀를 사용해야 하므로 활성화 함수로는 시그모이드 함수를 사용하고, 손실 함수로 크로스 엔트로피 함수를 사용합니다. 하이퍼파라미터인 배치 크기는 64이며, 15 에포크를 수행합니다. EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)는 검증 데이터 손실(val_loss)이 증가하면, 과적합 징후므로 검증 데이터 손실이 4회 증가하면 정해진 에포크가 도달하지 못하였더라도 학습을 조기 종료(Early Stopping)한다는 의미입니다. ModelCheckpoint를 사용하여 검증 데이터의 정확도(val_acc)가 이전보다 좋아질 경우에만 모델을 저장합니다. validation_split=0.2을 사용하여 훈련 데이터의 20%를 검증 데이터로 분리해서 사용하고, 검증 데이터를 통해서 훈련이 적절히 되고 있는지 확인합니다. 검증 데이터는 기계가 훈련 데이터에 과적합되고 있지는 않은지 확인하기 위한 용도로 사용됩니다. from tensorflow.keras.layers import Embedding, Dense, LSTM from tensorflow.keras.models import Sequential from tensorflow.keras.models import load_model from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint embedding_dim = 100 hidden_units = 128 model = Sequential() model.add(Embedding(vocab_size, embedding_dim)) model.add(LSTM(hidden_units)) model.add(Dense(1, activation='sigmoid')) es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4) mc = ModelCheckpoint('best_model.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(X_train, y_train, epochs=15, callbacks=[es, mc], batch_size=64, validation_split=0.2) 저자의 경우 조기 종료 조건에 따라서 9 에포크에서 훈련이 멈췄습니다. 훈련이 다 되었다면 테스트 데이터에 대해서 정확도를 측정할 차례입니다. 훈련 과정에서 검증 데이터의 정확도가 가장 높았을 때 저장된 모델인 'best_model.h5'를 로드합니다. loaded_model = load_model('best_model.h5') print(" 테스트 정확도: %.4f" % (loaded_model.evaluate(X_test, y_test)[1])) 테스트 정확도: 0.8544 테스트 데이터에서 85.44%의 정확도를 얻습니다. 위 코드는 뒤에서 이어질 네이버 쇼핑 리뷰 분류 실습과 한국어 스팀 리뷰 감성 분류 실습에서도 거의 동일하게 사용될 코드입니다. 3. 리뷰 예측해보기 임의의 리뷰에 대해서 예측하는 함수를 만들어보겠습니다. 기본적으로 현재 학습한 model에 새로운 입력에 대해서 예측값을 얻는 것은 model.predict()를 사용합니다. 그리고 model.fit()을 할 때와 마찬가지로 새로운 입력에 대해서도 동일한 전처리를 수행 후에 model.predict()의 입력으로 사용해야 합니다. def sentiment_predict(new_sentence): new_sentence = re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣 ]','', new_sentence) new_sentence = okt.morphs(new_sentence, stem=True) # 토큰화 new_sentence = [word for word in new_sentence if not word in stopwords] # 불용어 제거 encoded = tokenizer.texts_to_sequences([new_sentence]) # 정수 인코딩 pad_new = pad_sequences(encoded, maxlen = max_len) # 패딩 score = float(loaded_model.predict(pad_new)) # 예측 if(score > 0.5): print(“{:.2f}% 확률로 긍정 리뷰입니다.
“.format(score * 100)) else: print(“{:.2f}% 확률로 부정 리뷰입니다.
“.format((1 – score) * 100))
sentiment_predict(‘이 영화 개꿀잼 ㅋㅋㅋ’)
97.76% 확률로 긍정 리뷰입니다.
sentiment_predict(‘이 영화 핵노잼 ㅠㅠ’)
98.55% 확률로 부정 리뷰입니다.
sentiment_predict(‘이딴게 영화냐 ㅉㅉ’)
99.91% 확률로 부정 리뷰입니다.
sentiment_predict(‘감독 뭐하는 놈이냐?’)
98.21% 확률로 부정 리뷰입니다.
sentiment_predict(‘와 개쩐다 정말 세계관 최강자들의 영화다’)
80.77% 확률로 긍정 리뷰입니다.
ㄱ-ㅎ와 ㅏ-ㅣ 사이에 어떤 글자들이 포함되어져 있는지는 아래의 링크에서 확인할 수 있습니다.
https://www.unicode.org/charts/PDF/U3130.pdf
가-힣 사이에 어떤 글자들이 포함되어져 있는지는 아래의 링크에서 확인할 수 있습니다.
https://www.unicode.org/charts/PDF/UAC00.pdf
[python/NLP] 감정분류(한국어)- 리뷰데이터 학습, 평가, 예측까지
반응형
이번에 할 자연어처리 포스팅은 감정분류입니다 🙂
감정분류는 어떤 텍스트가 있을 때, 그 텍스트가 긍정인지, 부정인지 분류해 주는 것을 말합니다.
이번에 사용할 데이터는 감정분류 대표 예제인 네이버 영화 리뷰 데이터를 가지고
감정분류를 위한 전처리, 모델링, 학습, 예측까지 진행해 보도록 하겠습니다.
데이터 준비
https://github.com/e9t/nsmc
위의 링크에 들어가서
1. ratings.txt – 전체 리뷰데이터(20만건)
2. ratings_train.txt – 학습데이터(15만건)
3. ratings_test.txt – 평가데이터(5만건)
위의 세 파일을 다운받아 주세요.
그 후 DATA 라는 폴더를 만들어 그 안에 파일들이 위치하도록 해줍니다.
데이터 분석하기
감정분류에 사용할 데이터가 어떻게 이루어져있는지 살펴보도록 하겠습니다.
어떤 데이터고 길이는 어느정도 되는지, 많이 나온 단어 수 등등을 분석하면서 추후 모델링에 대한 좋은 아이디어가 생길 수도 있기 때문입니다.
import numpy as np import pandas as pd import os import matplotlib.pyplot as plt import seaborn as sns from wordcloud import WordCloud DATA_PATH = ‘/content/sample_data/DATA/’ #데이터경로 설정 print(‘파일 크기: ‘) for file in os.listdir(DATA_PATH): if ‘txt’ in file: print(file.ljust(30)+str(round(os.path.getsize(DATA_PATH+ file) / 100000,2))+’MB’)
파일 크기는 각각 위의 사진과 같습니다.
train은 전체 데이터의 75%, test는 25%정도 됩니다.
학습할 데이터를 확인해 보도록 하겠습니다.
#트레인 파일 불러오기 train_data = pd.read_csv(DATA_PATH + ‘ratings_train.txt’,header = 0, delimiter = ‘\t’, quoting=3) train_data.head()
train파일에서는 id, document(리뷰), label(긍정인지 부정인지) 이렇게 3가지 정보를 나타내는 컬럼이 있습니다.
print(‘학습데이터 전체 개수: {}’.format(len(train_data)))
학습데이터는 그전에 언급했듯이 15만건이 있습니다. 총 15만개의 행과 3개의 열로 이루어져 있습니다.
리뷰 길이들을 확인해 보겠습니다.
#리뷰 전체길이 확인 train_length = train_data[‘document’].astype(str).apply(len) train_length.head()
앞에 5행만 대표적으로 출력했을 때 각각 리뷰의 길이는 위와 같습니다.
#리뷰 통계 정보 print(‘리뷰 길이 최댓값: {}’.format(np.max(train_length))) print(‘리뷰 길이 최솟값: {}’.format(np.min(train_length))) print(‘리뷰 길이 평균값: {:.2f}’.format(np.mean(train_length))) print(‘리뷰 길이 표준편차: {:.2f}’.format(np.std(train_length))) print(‘리뷰 길이 중간값: {}’.format(np.median(train_length))) print(‘리뷰 길이 제1사분위: {}’.format(np.percentile(train_length,25))) print(‘리뷰 길이 제3사분위: {}’.format(np.percentile(train_length,75)))
리뷰 길이에 대해 간단한 통계 분석을 해보았을 때, 리뷰는 평균적으로 35.24의 길이를 가집니다.
이번에는 리뷰에서 어떤 단어가 가장 많이 나오는지 빈도분석을 워드클라우드(wordcloud)로 해 보겠습니다.
워드클라우드를 만들기 위한 전처리로 str타입이 아닌 데이터를 모두 제거해 줍니다.
# 문자열 아닌 데이터 모두 제거 train_review = [review for review in train_data[‘document’] if type(review) is str] train_review
한글을 시각화할 것이기 때문에 한글 폰트(.ttf파일)를 다운받아 DATA파일에 위치해 주세요.
그 후 워드클라우드 시각화를 진행해 줍니다.
# 한글 폰트 설정(.ttf파일 다운로드 후 실행) wordcloud = WordCloud(DATA_PATH+’폰트.ttf’).generate(‘ ‘.join(train_review)) plt.imshow(wordcloud, interpolation=’bilinear’) plt.axis(‘off’) plt.show()
영화, 진짜, 정말, 그냥, 너무 등등의 단어가 많이 나옴을 확인 가능합니다.
학습데이터의 긍정리뷰 및 부정리뷰가 얼만큼 되는지도 확인해 보겠습니다.
#긍정 1, 부정 0 print(‘긍정 리뷰 갯수: {}’.format(train_data[‘label’].value_counts()[1])) print(‘부정 리뷰 갯수: {}’.format(train_data[‘label’].value_counts()[0]))
각각 74827개(1: 긍정), 75173개(0: 부정)가 있습니다.
대략적인 분석을 마치도록 하겠습니다.
이번에는 데이터를 전처리하여 학습할 수 있는 데이터로 만들어 주도록 하겠습니다.
데이터 전처리
데이터 전처리는 5단계로 이루어져 있습니다.
1. 정규화로 한국어만 남기기
2. 형태소 분석기로 어간 추출하기
3. 불용어 제거하기
4. 문자를 인덱스벡터로 전환하기
5. 패딩처리하기
한국어 텍스트를 전처리할 때는 konlpy를 사용하여 형태소 분석 등을 해주겠습니다.
!pip install konlpy
konlpy가 미설치 되어 있다면 위의 코드를 실행해 주세요.
그 후 학습데이터의 리뷰데이터만 뽑아 보겠습니다.
import numpy as np import pandas as pd import re import json from konlpy.tag import Okt from tensorflow.keras.preprocessing.sequence import pad_sequences from tensorflow.keras.preprocessing.text import Tokenizer DATA_PATH = ‘/content/sample_data/DATA/’ # 데이터 경로 설정 train_data = pd.read_csv(DATA_PATH+’ratings_train.txt’, header = 0, delimiter=’\t’, quoting=3) train_data[‘document’][:5]
자 그럼 본격적으로 전처리를 시작해 보겠습니다.
1. 전처리를 도와주는 함수 만들기
#전처리 함수 만들기 def preprocessing(review, okt, remove_stopwords = False, stop_words =[]): #함수인자설명 # review: 전처리할 텍스트 # okt: okt객체를 반복적으로 생성하지 않고 미리 생성 후 인자로 받음 # remove_stopword: 불용어를 제거할지 여부 선택. 기본값 False # stop_words: 불용어 사전은 사용자가 직접 입력, 기본값 빈 리스트 # 1. 한글 및 공백 제외한 문자 모두 제거 review_text = re.sub(‘[^가-힣ㄱ-ㅎㅏ-ㅣ\\s]’,”,review) #2. okt 객체를 활용하여 형태소 단어로 나눔 word_review = okt.morphs(review_text,stem=True) if remove_stopwords: #3. 불용어 제거(선택) word_review = [token for token in word_review if not token in stop_words] return word_review
2. 전체 학습데이터 및 평가데이터 리뷰 전처리하기
# 전체 텍스트 전처리 stop_words = [‘은’,’는’,’이’,’가’,’하’,’아’,’것’,’들’,’의’,’있’,’되’,’수’,’보’,’주’,’등’,’한’] okt = Okt() clean_train_review = [] for review in train_data[‘document’]: # 리뷰가 문자열인 경우만 전처리 진행 if type(review) == str: clean_train_review.append(preprocessing(review,okt,remove_stopwords=True,stop_words= stop_words)) else: clean_train_review.append([]) #str이 아닌 행은 빈칸으로 놔두기 clean_train_review[:4]
#테스트 리뷰도 동일하게 전처리 test_data = pd.read_csv(DATA_PATH + ‘ratings_test.txt’, header = 0, delimiter=’\t’, quoting=3) clean_test_review = [] for review in test_data[‘document’]: if type(review) == str: clean_test_review.append(preprocessing(review, okt, remove_stopwords=True, stop_words=stop_words)) else: clean_test_review.append([])
3. 문자로 되어있는 리뷰데이터를 인덱스 벡터로 변환
학습데이터 리뷰로 단어 사전을 생성하여 리뷰데이터를 인덱스로 바꾸어 주도록 하겠습니다.
라벨데이터(긍정, 분석 감정데이터, 정답 데이터)는 벡터화 해줍니다.
# 인덱스 벡터 변환 후 일정 길이 넘어가거나 모자라는 리뷰 패딩처리 tokenizer = Tokenizer() tokenizer.fit_on_texts(clean_train_review) train_sequences = tokenizer.texts_to_sequences(clean_train_review) test_sequences = tokenizer.texts_to_sequences(clean_test_review) word_vocab = tokenizer.word_index #단어사전형태 MAX_SEQUENCE_LENGTH = 8 #문장 최대 길이 #학습 데이터 train_inputs = pad_sequences(train_sequences,maxlen=MAX_SEQUENCE_LENGTH,padding=’post’) #학습 데이터 라벨 벡터화 train_labels = np.array(train_data[‘label’]) #평가 데이터 test_inputs = pad_sequences(test_sequences,maxlen=MAX_SEQUENCE_LENGTH,padding=’post’) #평가 데이터 라벨 벡터화 test_labels = np.array(test_data[‘label’])
4. 전처리 완료된 데이터 넘파이 파일로 저장
이후 여기서 만들어준 데이터들을 학습시 사용이 용이하도록 넘파이 파일로 만들어 저장해주도록 하겠습니다.
DEFAULT_PATH = ‘/content/sample_data/’ # 경로지정 DATA_PATH = ‘CLEAN_DATA/’ #.npy파일 저장 경로지정 TRAIN_INPUT_DATA = ‘nsmc_train_input.npy’ TRAIN_LABEL_DATA = ‘nsmc_train_label.npy’ TEST_INPUT_DATA = ‘nsmc_test_input.npy’ TEST_LABEL_DATA = ‘nsmc_test_label.npy’ DATA_CONFIGS = ‘data_configs.json’ data_configs={} data_configs[‘vocab’] = word_vocab data_configs[‘vocab_size’] = len(word_vocab) + 1 #전처리한 데이터들 파일로저장 import os if not os.path.exists(DEFAULT_PATH + DATA_PATH): os.makedirs(DEFAULT_PATH+DATA_PATH) #전처리 학습데이터 넘파이로 저장 np.save(open(DEFAULT_PATH+DATA_PATH+TRAIN_INPUT_DATA,’wb’),train_inputs) np.save(open(DEFAULT_PATH+DATA_PATH+TRAIN_LABEL_DATA,’wb’),train_labels) #전처리 테스트데이터 넘파이로 저장 np.save(open(DEFAULT_PATH+DATA_PATH+TEST_INPUT_DATA,’wb’),test_inputs) np.save(open(DEFAULT_PATH+DATA_PATH+TEST_LABEL_DATA,’wb’),test_labels) #데이터 사전 json으로 저장 json.dump(data_configs,open(DEFAULT_PATH + DATA_PATH + DATA_CONFIGS,’w’),ensure_ascii=False)
저는 CLEAN_DATA라는 폴더에 저장해 주었습니다.
학습하기
1. 학습데이터 및 전처리 데이터 불러오기
# 학습 데이터 불러오기 import tensorflow as tf from tensorflow.keras.preprocessing.sequence import pad_sequences from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint from tensorflow.keras import layers import numpy as np import pandas as pd import matplotlib.pyplot as plt import os import json from tqdm import tqdm #전처리 데이터 불러오기 DATA_PATH = ‘/content/sample_data/CLEAN_DATA/’ DATA_OUT = ‘/content/sample_data/DATA_OUT/’ INPUT_TRAIN_DATA = ‘nsmc_train_input.npy’ LABEL_TRAIN_DATA = ‘nsmc_train_label.npy’ DATA_CONFIGS = ‘data_configs.json’ train_input = np.load(open(DATA_PATH + INPUT_TRAIN_DATA,’rb’)) train_input = pad_sequences(train_input,maxlen=train_input.shape[1]) train_label = np.load(open(DATA_PATH + LABEL_TRAIN_DATA,’rb’)) prepro_configs = json.load(open(DATA_PATH+DATA_CONFIGS,’r’))
2. 파라미터 세팅하기
model_name= ‘cnn_classifier_kr’ BATCH_SIZE = 512 NUM_EPOCHS = 10 VALID_SPLIT = 0.1 MAX_LEN = train_input.shape[1] kargs={‘model_name’: model_name, ‘vocab_size’:prepro_configs[‘vocab_size’],’embbeding_size’:128, ‘num_filters’:100,’dropout_rate’:0.5, ‘hidden_dimension’:250,’output_dimension’:1}
3. 모델 함수 만들기
학습 모델은 CNN분류 모델로 학습을 진행하도록 하겠습니다.
class CNNClassifier(tf.keras.Model): def __init__(self, **kargs): super(CNNClassifier, self).__init__(name=kargs[‘model_name’]) self.embedding = layers.Embedding(input_dim=kargs[‘vocab_size’], output_dim=kargs[’embbeding_size’]) self.conv_list = [layers.Conv1D(filters=kargs[‘num_filters’], kernel_size=kernel_size, padding=’valid’,activation = tf.keras.activations.relu, kernel_constraint = tf.keras.constraints.MaxNorm(max_value=3)) for kernel_size in [3,4,5]] self.pooling = layers.GlobalMaxPooling1D() self.dropout = layers.Dropout(kargs[‘dropout_rate’]) self.fc1 = layers.Dense(units=kargs[‘hidden_dimension’], activation = tf.keras.activations.relu, kernel_constraint=tf.keras.constraints.MaxNorm(max_value=3.)) self.fc2 = layers.Dense(units=kargs[‘output_dimension’], activation=tf.keras.activations.sigmoid, kernel_constraint= tf.keras.constraints.MaxNorm(max_value=3.)) def call(self,x): x = self.embedding(x) x = self.dropout(x) x = tf.concat([self.pooling(conv(x)) for conv in self.conv_list], axis = 1) x = self.fc1(x) x = self.fc2(x) return x
4. 학습하기
에포크는 10으로 주어 학습을 진행하고, 검증 정확도가 그전보다 낮아지면 학습을 멈추도록 설계하였습니다.
from tensorflow.keras.models import save_model model = CNNClassifier(**kargs) model.compile(optimizer=tf.keras.optimizers.Adam(), loss = tf.keras.losses.BinaryCrossentropy(), metrics = [tf.keras.metrics.BinaryAccuracy(name=’accuracy’)]) #검증 정확도를 통한 EarlyStopping 기능 및 모델 저장 방식 지정 earlystop_callback = EarlyStopping(monitor=’val_accuracy’, min_delta=0.0001, patience=2) checkpoint_path = DATA_OUT + model_name +’\weights.h5′ checkpoint_dir = os.path.dirname(checkpoint_path) if os.path.exists(checkpoint_dir): print(“{} — Folder already exists
“.format(checkpoint_dir)) else: os.makedirs(checkpoint_dir, exist_ok=True) print(“{} — Folder create complete
“.format(checkpoint_dir)) cp_callback = ModelCheckpoint( checkpoint_path, monitor = ‘val_accuracy’, verbose=1, save_best_only = True, save_weights_only=True ) history = model.fit(train_input, train_label, batch_size=BATCH_SIZE, epochs = NUM_EPOCHS, validation_split=VALID_SPLIT, callbacks=[earlystop_callback, cp_callback]) # 모델 저장하기 save_model(model,’모델 저장할 폴더 경로’)
평가하기
위에서 학습한 모델이 저장이 되었고, 그 저장된 모델을 가지고 평가데이터를 넣어 얼마나 정답을 맞추는지 검증해 보도록 하겠습니다.
INPUT_TEST_DATA = ‘nsmc_test_input.npy’ LABEL_TEST_DATA = ‘nsmc_test_label.npy’ SAVE_FILE_NM = ‘weights.h5′ test_input = np.load(open(DATA_PATH+INPUT_TEST_DATA,’rb’)) test_input = pad_sequences(test_input,maxlen=test_input.shape[1]) test_label_data = np.load(open(DATA_PATH + LABEL_TEST_DATA, ‘rb’)) model.load_weights(‘모델저장위치/weights.h5’) model.evaluate(test_input, test_label_data)
약 82.6%의 정확도를 보입니다.
예측하기
마지막으로, 저장된 학습모델을 가지고 새로운 문장이 있을 때 그 문장이 긍정인지 부정인지 예측해 보겠습니다.
import numpy as np import pandas as pd import re import json from konlpy.tag import Okt from tensorflow.keras.preprocessing.sequence import pad_sequences from tensorflow.keras.preprocessing.text import Tokenizer okt = Okt() tokenizer = Tokenizer() DATA_CONFIGS = ‘data_configs.json’ prepro_configs = json.load(open(‘/content/sample_data/CLEAN_DATA/’+DATA_CONFIGS,’r’)) prepro_configs[‘vocab’] = word_vocab tokenizer.fit_on_texts(word_vocab) MAX_LENGTH = 8 #문장최대길이 sentence = input(‘감성분석할 문장을 입력해 주세요.: ‘) sentence = re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣\\s ]’,”, sentence) stopwords = [‘은’,’는’,’이’,’가’,’하’,’아’,’것’,’들’,’의’,’있’,’되’,’수’,’보’,’주’,’등’,’한’] # 불용어 추가할 것이 있으면 이곳에 추가 sentence = okt.morphs(sentence, stem=True) # 토큰화 sentence = [word for word in sentence if not word in stopwords] # 불용어 제거 vector = tokenizer.texts_to_sequences(sentence) pad_new = pad_sequences(vector, maxlen = MAX_LENGTH) # 패딩 model.load_weights(‘/content/sample_data/DATA_OUT/cnn_classifier_kr\weights.h5’) #모델 불러오기 predictions = model.predict(pad_new) predictions = float(predictions.squeeze(-1)[1]) if(predictions > 0.5): print(“{:.2f}% 확률로 긍정 리뷰입니다.
“.format(predictions * 100)) else: print(“{:.2f}% 확률로 부정 리뷰입니다.
“.format((1 – predictions) * 100))
이렇게 직접 리뷰 문장을 입력하여 긍정리뷰인지 부정리뷰인지 확인이 가능합니다 🙂
전체 코드
https://colab.research.google.com/drive/1PkuR9r9WrAXHBq3TLePCiOEgYwuFx2lO?usp=sharing
학습된 모델파일
https://drive.google.com/drive/folders/13FqdLc-8BbtMptJZgtaN390Ot96J8I4y?usp=sharing
my_models.zip파일입니다.
Github
https://github.com/ElenaLim/NLP_EmotionA.git
전처리, 학습, 검증, 예측의 각 파트가 분리된 .py 파일이 있습니다.
참고자료
책 – 텐서플로2와 머신러닝으로 시작하는 자연어처리
마무리
오늘 감정분석 대표적인 영화리뷰 데이터로 감정분류를 해 보았는데
개인적으로는 예측 부분이 가장 재밌는것 같습니다 ㅎㅎ
다른 오픈데이터도 있다면 시간될 때 다른 모델, 데이터로 감정 분류를 진행해 보도록 하겠습니다 🙂
++22.06.09 : 모델 저장부분 추가 및 학습된 모델 업로드
++22.09.07: 전처리, 학습, 검증, 예측 파트로 분리된 각각의 .py파일 추가(깃허브 링크)
반응형
[Python] 소셜 데이터의 감성 예측
미리 크롤링한 영화 댓글 자료
from sklearn . linear_model import LogisticRegression from sklearn . model_selection import GridSearchCV clf = LogisticRegression ( random_state = 0 ) params = { ‘C’ : [ 15 , 18 , 19 , 20 , 22 ] } grid_cv = GridSearchCV ( clf , param_grid = params , cv = 3 , scoring = ‘accuracy’ , verbose = 1 ) grid_cv . fit ( tfv_train_x , train_y ) print ( grid_cv . best_params_ , grid_cv . best_score_ )
【실습】 Python >> Text Mining — 감성 분류 분석 (호텔 리뷰 데이터)
제주 호텔의 리뷰 데이터(평가 점수 + 평가 내용)을 활용해 다음 2가지 분석을 진행합니다:
>> 사용할 Library
>> 사용할 데이터셋
Tripadvisor 여행사이트에서 “제주 호텔”로 검색해서 나온 리뷰들을 활용합니다. (평점 & 평가 내용 포함)
>> Feature Description
“text” 내용을 확인해보면, 소량의 “특수 문자”와 “모음”이 존재하는 경우가 있습니다. 이들은 Text Mining을 적용할 의미가 없기 때문에 정규표현식을 이용해서 제거해보도록 할게요.
기계가 텍스트 형식으로 되어 있는 리뷰 데이터를 이해하려면, 텍스트 데이터를 단어 단위로 분리하는 전처리 괴정이 필요합니다. 여기서 분리된 단어들은 Bag of Words로 Count 기반으로 나타날 수도 있고, TF-IDF를 통해서 점수로 나타날 수도 있습니다.
먼저 리뷰의 평가 내용을 단어화해서 형태소를 추출하고, 그 다음 Bag of Words를 생성하여 TF-IDF 변환을 진행하겠습니다.
영문이 아닌 한글을 처리해야 하기 때문에 “konlpy”이라는 library를 사용합니다.
Requirement already satisfied: konlpy==0.5.2 in d:\anaconda\lib\site-packages (0.5.2) Requirement already satisfied: jpype1 in d:\anaconda\lib\site-packages (1.0.2) Requirement already satisfied: Jpype1-py3 in d:\anaconda\lib\site-packages (0.5.5.4) Requirement already satisfied: tweepy>=3.7.0 in d:\anaconda\lib\site-packages (from konlpy==0.5.2) (3.9.0) Requirement already satisfied: lxml>=4.1.0 in d:\anaconda\lib\site-packages (from konlpy==0.5.2) (4.5.0) Requirement already satisfied: colorama in d:\anaconda\lib\site-packages (from konlpy==0.5.2) (0.4.3) Requirement already satisfied: numpy>=1.6 in d:\anaconda\lib\site-packages (from konlpy==0.5.2) (1.18.1) Requirement already satisfied: beautifulsoup4==4.6.0 in d:\anaconda\lib\site-packages (from konlpy==0.5.2) (4.6.0) Requirement already satisfied: typing-extensions; python_version < "3.8" in d:\anaconda\lib\site-packages (from jpype1) (3.7.4.1) Requirement already satisfied: requests[socks]>=2.11.1 in d:\anaconda\lib\site-packages (from tweepy>=3.7.0->konlpy==0.5.2) (2.23.0) Requirement already satisfied: requests-oauthlib>=0.7.0 in d:\anaconda\lib\site-packages (from tweepy>=3.7.0->konlpy==0.5.2) (1.3.0) Requirement already satisfied: six>=1.10.0 in d:\anaconda\lib\site-packages (from tweepy>=3.7.0->konlpy==0.5.2) (1.14.0) Requirement already satisfied: chardet<4,>=3.0.2 in d:\anaconda\lib\site-packages (from requests[socks]>=2.11.1->tweepy>=3.7.0->konlpy==0.5.2) (3.0.4) Requirement already satisfied: certifi>=2017.4.17 in d:\anaconda\lib\site-packages (from requests[socks]>=2.11.1->tweepy>=3.7.0->konlpy==0.5.2) (2020.6.20) Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in d:\anaconda\lib\site-packages (from requests[socks]>=2.11.1->tweepy>=3.7.0->konlpy==0.5.2) (1.25.8) Requirement already satisfied: idna<3,>=2.5 in d:\anaconda\lib\site-packages (from requests[socks]>=2.11.1->tweepy>=3.7.0->konlpy==0.5.2) (2.9) Requirement already satisfied: PySocks!=1.5.7,>=1.5.6; extra == “socks” in d:\anaconda\lib\site-packages (from requests[socks]>=2.11.1->tweepy>=3.7.0->konlpy==0.5.2) (1.7.1) Requirement already satisfied: oauthlib>=3.0.0 in d:\anaconda\lib\site-packages (from requests-oauthlib>=0.7.0->tweepy>=3.7.0->konlpy==0.5.2) (3.1.0)
[파이썬] 네이버 클로바 Sentiment 문장 텍스트 감정 분석
반응형
바빠서 시간이 부족하거나 파이썬 코딩이 처음인 사람들이 많다. 누구나 손쉽게 코딩을 배우고 바로 업무자동화,디지털마케팅 등에 쓰일만한 여러 가지 파이썬 코드를 만들고 있다. 이에 파이썬 구글 블로거 API 자동 포스팅하기 를 통해 파이썬 코드 공유드린다. 이에 오늘 하루도 여러분들의 컴퓨터 업무에 자유로운 나날이 길어지길 바란다. 오늘은 네이버 클라우드 서비스 내에 보이는 API를 가져왔다. 이름하여 네이버 Sentiment API 라고 하는데, 이는 텍스트에 담긴 감정(긍정/부정/중립)을 분석해 주는 API라고 한다.
파이썬 네이버 sentiment 긍정 부정 판별 분석
https://www.ncloud.com/product/aiService/clovaSentiment
거기에 들어가서 네이버 Sentiment API 이용 신청하고, client id 와 client secret 키만 받으면 완료된다. 그럼 긍정 부정 단어를 얼마나 잘 판별해 주는지 테스트해볼까? 아래는 테스트할 컨텐츠 텍스트들을 여러가지를 집어넣어봤다.
네이버 클로바 Sentiment 문장 텍스트 감정 분석
하기 코딩은 json으로 위에 보여진 메모장 내 텍스트를 얼마나 긍정, 부정으로 판별해 줄까가 궁금해서 넣어보았다. 800단어씩 시범으로 돌려보기로 한다.(1000~1500자까지 된다고는 하는데, 이상하게 에러가 발생되는경우가 있어서 800단어로 세팅했다.)
import json file = open(‘C:/Users/user/raw/naver_blog/positive_negative_text_result.txt’, ‘w’, encoding=’utf8′) #결과파일 n = 1 #첫번째 m = 800 #두번째 for i in range(1, 2) : #41번 client_id = “” #클라이언트 키 client_secret = “” #클라이언트 시크릿 키 url=”https://naveropenapi.apigw.ntruss.com/sentiment-analysis/v1/analyze” headers = { “X-NCP-APIGW-API-KEY-ID”: client_id, “X-NCP-APIGW-API-KEY”: client_secret, “Content-Type”: “application/json” } f = open(‘C:/Users/user/raw/naver_blog/blog_content.txt’, ‘r’, encoding=’utf8′) text = f.read() text_2 = text.replace(”
“, “”) text_3 = text_2.replace(“________________”, ” “) content = text_3[n:m] #800단어씩 data = { “content”: content } print(json.dumps(data, indent=4, sort_keys=True)) response = requests.post(url, data=json.dumps(data), headers=headers) rescode = response.status_code if(rescode == 200): print (response.text) else: print(“Error : ” + response.text) f.close() text = response.json() raw = text[‘sentences’] max_cnt = len(raw) #리스트 개수 for i in range(0, max_cnt) : content = str(raw[i][‘content’]) #텍스트 offset = int(raw[i][‘highlights’][0][‘offset’]) #오프셋 length = int(raw[i][‘highlights’][0][‘length’]) #해당 길이 text = content[offset : offset + length] #부정 의미가 있는 문구 텍스트 추출 #print(text) file.write(str(text) + ‘
‘) n += 800 m += 800 file.close()
먼저 아래와 같이 나오긴 했는데, 보아하니 문장 1줄을 읽고, 이에 빠른 offset, 해당 문장 길이(length), 그리고 sentiment 판별결과 (긍정, 부정, 중립 이렇게 있는것 같다.) 이외 confidence 라고 해서 각 negative, positive, neutral 등의 지수를 적어주는 것 같다. highlights 는 해당 분석된 문장을 보여주는것 같다. 그럼 긍정 텍스트가 담긴 텍스트만 뽑아볼까?
네이버 클로바 Sentiment 문장 텍스트 감정 분석
아래는 해당 텍스트된 문장에서 긍정 의미를 가진 걸로 판명된 문장만 따로 텍스트 추출하는 걸로 해봤다.
max_cnt = len(raw) #리스트 개수 for i in range(0, max_cnt) : if (raw[i][‘sentiment’] == ‘positive’) : #긍정 의미를 가질경우 content = str(raw[i][‘content’]) #텍스트 offset = int(raw[i][‘highlights’][0][‘offset’]) #오프셋 length = int(raw[i][‘highlights’][0][‘length’]) #해당 길이 text = content[offset : offset + length] #긍정 의미가 있는 문구 텍스트 추출 print(text)
밑에가 그 결과다. 보아하니 긍정적인 부문만 잘 긁어서 가져다 보는것 같다. (역시 네이버 AI 기술도 좋다..)
보아하니 이런식으로 긍정, 부정 의미가 담긴 리뷰를 저렇게 판별 분석을 해서 뭔가 이용한다면은 굉장히 긍정적인 용도로 쓸 수 있을 것 같다. 차후엔 텍스트 추출 이후 해당 텍스트 내 감정 분석 등을 통해 좋은 부문을 광고 문구 등에 응용할 수 있는 방안도 찾아보면 좋을 것 같다.
네이버 클로바 Sentiment 문장 텍스트 감정 분석
반응형
감성 분석 — 데이터 사이언스 스쿨
–2018-12-06 20:07:59– https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt Resolving raw.githubusercontent.com (raw.githubusercontent.com)… 151.101.72.133 Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.72.133|:443… connected. HTTP request sent, awaiting response… 200 OK Length: 14628807 (14M) [text/plain] Saving to: ‘ratings_train.txt’ ratings_train.txt 100%[===================>] 13.95M 7.27MB/s in 1.9s 2018-12-06 20:08:02 (7.27 MB/s) – ‘ratings_train.txt’ saved [14628807/14628807] –2018-12-06 20:08:02– https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt Resolving raw.githubusercontent.com (raw.githubusercontent.com)… 151.101.72.133 Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.72.133|:443… connected. HTTP request sent, awaiting response… 200 OK Length: 4893335 (4.7M) [text/plain] Saving to: ‘ratings_test.txt’ ratings_test.txt 100%[===================>] 4.67M 5.31MB/s in 0.9s 2018-12-06 20:08:03 (5.31 MB/s) – ‘ratings_test.txt’ saved [4893335/4893335] CPU times: user 114 ms, sys: 52.2 ms, total: 166 ms Wall time: 4.11 s
[Python] 뉴스 감성지수 분류 모델
728×90
반응형
https://sieon-dev.tistory.com/4
위 사이트를 개발할 때 사용한 감성지수 분류 모델에 대해 기록을 남겨볼까 합니다.
Preview
사실 처음에는 뉴스 데이터를 활용하여 다음날의 주가를 예측하는 모델을 만들고 싶었지만 다양한 방법들을 시도하여도 예측 정확도가 60%대 밖에 나오지 않아 차라리 감성지수를 예측하는 모델을 설계하는 방향으로 바꿨습니다.
감성지수는 영화 리뷰와 같이 리뷰와 평점이 있는 데이터를 학습시켜 새로운 리뷰가 달렸을 때 해당 리뷰의 감성(감정) 값을 예측하는 모형에 많이 사용됩니다. 이 방법론을 적용하여 뉴스와 뉴스가 나온 다음 날의 주가를 학습시켜 다음날 주가를 예측하는 모델을 만들어보자 했던 것이 처음 시도였고 이게 정확도가 높지가 않아 그럼 뉴스와 뉴스의 감성 분류 값을 학습시키는 모델로 바뀌었던 것이죠.
영화 리뷰같은 경우는 사용자가 리뷰를 남김과 동시에 별점을 남기기 때문에 종속변수를 손쉽게 라벨링(긍정이면 1, 부정이면 0)할 수 있지만 뉴스는 그렇지 않아 이 뉴스를 긍정으로 봐야 할지 부정으로 봐야 할지 정하는 것이 정말 애매합니다. 그래서 저는 제가 개발한 방법대로 감성사전을 만들었습니다. 예를 들어 어제 “FOMC 금리 인상 가능성 있어”와 같은 제목의 뉴스가 나왔고 오늘 코스피 종가가 어제보다 올랐으면 “FOMC”, “금리”, “인상”, “가능성” (“있어”는 명사가 아니므로)에 긍정 점수를 부여하고 반대로 떨어졌으면 부정 점수를 부여하는 방식으로 말이죠. 이렇게 만든 감성사전의 모든 단어들의 평균점수보다 새로운 뉴스의 단어들의 평균점수가 높으면 1, 아니면 0으로 라벨링을 한 후 학습을 진행했습니다. 다행히도 이 모델의 감성 분류 예측 정확도를 보니 91%까지 올랐습니다.
1. 데이터 수집
뉴스 데이터는 빅카인즈 에서 경제 섹터의 뉴스를 2017년 1월 1일부터 2021년 3월 30일까지 총 500,194 건을 수집하였습니다.
2. 데이터 전처리
뉴스의 제목만을 사용하기 때문에 날짜와 제목을 제외한 컬럼은 제거 후 야후 파이낸스에서 Kospi 데이터를 다운로드하여 뉴스데이터에 붙였습니다. 뉴스와 뉴스가 나온 다음날 코스피 종가가 전날 대비 상승했으면 1, 아니면 0으로 말이죠. 추가로 불용어를 제거하고 Okt 라이브러리를 사용해서 명사만을 추출한 칼럼을 추가했습니다.
okt = Okt() n_ = [] title_rename = [] for i in range(len(df)): if(i % 10000 ==0): print(i,”단계 완료”) title_rename.append(re.sub(“[\(\[].*?[\)\]]”, “”,df.iloc[i][‘제목’])) n_.append(‘ ‘.join(okt.nouns(df.iloc[i][‘제목’]))) df[‘nouns’] = n_ df[‘제목’]=title_rename df = df[df[‘nouns’]!=”] #2차 불용어 제거 df[‘제목’] = df[‘제목’].str.replace(“[^ㄱ-ㅎㅏ-ㅣ가-힣 ]”,””) df[‘제목’].replace(”, np.nan, inplace=True) df = df.dropna(how=’any’)
라벨의 비율 1: 269861 0: 228765
Train : Test의 비율 400000 : 98626 로 분할 후 빈 행 제거
3. 감성사전 구축
한 글자인 단어는 제거하고 두 글자 이상인 단어들의 점수를 초기화해주었습니다.
총 47229개의 단어가 등장했습니다.
up = 269861 down = 228765 up_ratio = up/(up+down) down_ratio = down/(up+down) import collections for i,w in enumerate(df[‘nouns’]): w = w.split(‘ ‘) if (df.iloc[i][‘updown’]==1): for j in range(len(w)): noun = w[j] if len(noun)<=1: continue vocab[noun] = vocab[noun] + down_ratio else: for j in range(len(w)): noun = w[j] if len(noun)<=1: continue vocab[noun] = vocab[noun] - up_ratio 이 처럼 상승비율과 하락비율을 정의해준 다음 라벨 값이 1이면 하락 비율을 각 단어에 더해주고 라벨값이 0이면 상승 비율을 차감해주었습니다. 라벨값이 1이면 상승인데 왜 상승 비율을 더해주지 않았냐면 만약 라벨값이 1인 데이터가 아닌 데이터보다 훨씬 많다면 해당 단어들의 점수가 너무 커져서 점수가 고르지 못한 감성사전이 만들어지기 때문에 정규화를 해준 셈이죠. 결과는 이렇습니다. 감성사전 이제 만들어진 감성사전을 활용하여 뉴스의 평균 감성 점수를 산출한 뒤 칼럼에 추가했습니다. total = [] for i,w in enumerate(df_train['nouns']): sent_score = 0 w= w.split(' ') for j in w: if(len(j)<=1): continue elif(j not in sent_dictionary): continue else: sent_score = sent_score + sent_dictionary[j] total.append(sent_score/len(w)) df_train['sent_score'] = total Train Set *감성사전을 만들 땐 전체 데이터를 사용하여 만들었기 때문에 어떻게 보면 Train set에 Test set의 정보까지도 들어가 있는 문제가 있습니다. 처음 모델을 만들 땐 Train set만을 사용해서 감성사전을 만들었지만 Test set에 있는 단어들이 들어가지 않는다는 문제점(예를 들어 코로나)이 있어 최종 웹에 Deploy 하기 위한 모델은 전체 데이터를 사용해서 감성사전을 구축했습니다. 이후 sent_score가 감성사전의 평균 점수보다 높으면 1, 낮으면 0으로 새롭게 라벨링을 해주었습니다. sum = 0 for i in range(len(vocab)): sum = sum + list(vocab.values())[i] sent_mean = sum/len(vocab) a_ = [] for i in range(len(df_train)): if(df_train.iloc[i]['sent_score']>sent_mean): a_.append(1) else: a_.append(0) df_train[‘sent_label’] = a_
위 과정을 Test set에도 적용하여 데이터 전처리를 완료하였습니다.
4. 모델링
모델링하기에 앞서 Colab에서 형태소 분류기인 Mecab 설치를 해줘야 합니다. 앞서 감성사전을 구축할 땐 Okt 라이브러리를 사용했지만 Mecab이 성능이 훨씬 빠르기 때문에 Mecab으로 넘어왔습니다.
#Mecab 설치 !git clone https://github.com/SOMJANG/Mecab-ko-for-Google-Colab.git %cd Mecab-ko-for-Google-Colab !bash install_mecab-ko_on_colab190912.sh !pip install Mecab
모델링에는 Bi-LSTM 모델을 사용하였습니다. Bert도 사용해봤지만 성능면에서는 Bi-LSTM이 미세한 차이로 좋게 나왔습니다.
우선 validation set과 train set을 나눠준 뒤 형태소를 분류하고 X와 Y 값을 지정해줍니다.
train_data, validation_data = train_test_split(df_train, test_size = 0.2, random_state = 42) train_data.dropna(how=’any’,inplace= True) validation_data.dropna(how=’any’, inplace=True) mecab = Mecab() train_data[‘tokenized’] = train_data[‘제목’].apply(mecab.morphs) validation_data[‘tokenized’] = validation_data[‘제목’].apply(mecab.morphs) X_train = train_data[‘tokenized’].values Y_train = train_data[‘sent_label’].values X_vali= validation_data[‘tokenized’].values Y_vali = validation_data[‘sent_label’].values
이후 keras의 Tokenizer를 사용해 텍스트를 시퀀스 벡터로 변환합니다. (모델의 Input으로는 텍스트가 들어갈 수 없기 때문)
#vocab_size는 단어 집합의 크기 tokenizer = Tokenizer(vocab_size, oov_token = ‘OOV’) tokenizer.fit_on_texts(X_train) X_train = tokenizer.texts_to_sequences(X_train) X_vali = tokenizer.texts_to_sequences(X_vali)
X_train의 형태
일정한 Input 형태를 만들기 위해 적절한 길이를 지정하고 padding 과정으로 마무리합니다.
def below_threshold_len(max_len, nested_list): cnt = 0 for s in nested_list: if(len(s) <= max_len): cnt = cnt + 1 print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s'%(max_len, (cnt / len(nested_list))*100)) max_len = 30 below_threshold_len(max_len, X_train) X_train = pad_sequences(X_train, maxlen = max_len) X_vali = pad_sequences(X_vali, maxlen = max_len) 이제 모델을 구현하겠습니다. model = Sequential() model.add(Embedding(vocab_size, 100)) model.add(Bidirectional(LSTM(100))) model.add(Dense(1, activation='sigmoid')) es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4) mc = ModelCheckpoint('best_model.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(X_train, Y_train, epochs=15, callbacks=[es, mc], batch_size=256, validation_split=0.2) 모델 실행결과 Validation Set의 예측 정확도는 0.92가 나왔습니다. 이제 Test Set 도 같은 과정을 거쳐 전처리를 한 후 성능을 확인해보겠습니다. Test Set의 정확도 역시 0.91로 높은 성능을 보이고 있습니다. 이후 이 모델을 웹 서버에 Deploy 하여 네이버 News API를 통해 수집한 뉴스들을 분석하는 데 사용하고 있습니다. 많은 분께 도움이 되는 포스트였으면 좋겠습니다. 추후 이 모델을 파이썬 Django에서 어떻게 사용하는지도 포스팅하겠습니다. 반응형
한국어 감성분석, 감성 기반 추천 시스템 제작
728×90
SMALL
3달 여간의 교육을 받으며 파이썬부터 시작해서 ML, DL의 기초 OpenCV를 간단하게 다뤄보았다.
배운 것들을 토대로 모델을 만드는 프로젝트를 진행했다. (Jupyter notebook사용)
최대한 특이한걸 해보고 싶었지만 실력부족, 아이디어부족 등등.. 결국 뻔하디 뻔한 그런 주제로 들어온 것 같지만 그래도 3달여간 다른 3명의 팀원들과 함께 매일 저녁 6시부터 10시까지 함께 고생하며 완성한 첫 프로젝트인만큼 꽤나 기억에 많이 남을 것 같다.
간단하게 기록을 남긴다.
DS01.csv 0.84MB
데이터셋은 3가지 종류를 사용했다. AI hub 개편 전에 있던 한국어 연속성대화셋, 단발성 대화셋을 합쳐서 하나
깃허브에 있는 네이버 영화리뷰, 네이버 쇼핑리뷰.
스팀 게임리뷰는 워낙 거기에 있는 단어들이 유니크한 것들이 많았기 때문에 정확도가 떨어지고 범용성이 적다고 생각하여 제외하여 이렇게 3개만 사용했다. 이것도 42만개정도 되는 양이니 아주 적은 양은 아니었다.
먼저 간단하게 사용한 모듈을 보자
import pandas as pd import numpy as np %matplotlib inline import matplotlib.pyplot as plt import re import urllib.request from konlpy.tag import Okt from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences from collections import Counter from sklearn.model_selection import train_test_split
아!! python 3.8, Okt를 사용하기 위해 Jpype까지 설치해주었고 별도의 가상환경을 만들어서 그곳에서 개발하였다!!
개발환경 만드는 것도 헷갈려서 3일 걸렸다.
먼저 DS01파일을 보자.
data = pd.read_csv(‘DS01.csv’) data
사실 AI hub에 있는 대화세트는 7가지의 감정으로 분류가 되어있었는데, 처음에는 이것만으로 딥러닝을 진행하였으나 데이터량과 단어의 수에 비해 분류해야할 항목이 많다보니 정확도가 7%가 나와버리는…대참사가 일어났기 때문에 부정과 긍정으로 나누어서 진행했다.
data[‘발화’].nunique(), data[‘감정_int’].nunique() data.isnull().sum() data.drop_duplicates(subset = [“발화”], inplace = True)
null값을 확인하고 중복값을 제거해주었다.
다음
urllib.request.urlretrieve(“https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/naver_shopping.txt”, filename=”ratings_total.txt”) shop_data = pd.read_table(‘ratings_total.txt’, names=[‘ratings’, ‘발화’]) print(‘전체 리뷰 개수 :’,len(shop_data)) # 전체 리뷰 개수 출력
전체 리뷰 개수 : 200000
ratings(별점)
발화 (리뷰내용)
데이터프레임꼴로 만들었다.
shop_data[‘감정_int’] = np.select([shop_data.ratings > 3], [1], default=0) shop_data[4000:4005]
리뷰점수 4,5점은 긍정. 1,2점은 부정. 3점은 중립이라 넣지 않았다.
이렇게 분류해서 감정_int라는 행으로 추가해주었다.
왜냐..이따 데이터를 합칠거니까
이렇게 하고 난 후에 뭐가 있는지 보자
shop_data[‘ratings’].nunique(), shop_data[‘발화’].nunique(), shop_data[‘감정_int’].nunique()
(4, 199908, 2)
shop_data.drop_duplicates(subset=[‘발화’], inplace=True) # reviews 열에서 중복인 내용이 있다면 중복 제거 print(‘총 샘플의 수 :’,len(shop_data))
총 샘플의 수 : 199908
print(shop_data.isnull().values.any())
False
null값이 있는지 확인했는데 없다.
이렇게 정리한 쇼핑데이터를 확인해보자.
shop_data = shop_data.drop([‘ratings’], axis = 1) shop_data
ds01과 같은 꼴로 잘 다듬었다.
이제 둘을 concat으로 붙여준다.
Data = pd.concat([data, shop_data])
잘 붙었다. 데이터셋 21만여개 확보 완료
이제 같은 방식으로 영화리뷰도 붙여주면 된다.
영화리뷰는 깃에 train, test로 나뉘어있기 때문에 두번해줘야된다.
urllib.request.urlretrieve(“https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt”, filename=”ratings_train.txt”) urllib.request.urlretrieve(“https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt”, filename=”ratings_test.txt”) movie1_data = pd.read_table(‘ratings_train.txt’) movie2_data = pd.read_table(‘ratings_test.txt’) #쓸모없는 행 삭제 movie1_data = movie1_data.drop([‘id’], axis=1) movie2_data = movie2_data.drop([‘id’], axis=1) #행 이름 맞춰줌 movie1_data.columns=[‘발화’, ‘감정_int’] movie2_data.columns=[‘발화’, ‘감정_int’] #데이터 합체 Data = pd.concat([Data, movie1_data, movie2_data])
이제 이렇게 합쳐진 데이터를 train, test셋으로 나눠주자.
보통 25%를 테스트셋으로 활용한다는데 우리는 학습데이터양을 늘리기 위해 10%만 떼어냈다.
train, test = train_test_split(Data, test_size=0.1, random_state=210617) print(‘훈련용 리뷰의 개수 :’, len(train)) print(‘테스트용 리뷰의 개수 :’, len(test))
훈련용 리뷰의 개수 : 372584
테스트용 리뷰의 개수 : 41399
학습이 편향되지 않기 위해서는 label이 균일하게 분포되어있는 지 확인해주어야 한다.
train[‘감정_int’].value_counts().plot(kind = ‘bar’) print(train.groupby(‘감정_int’).size().reset_index(name = ‘count’))
다행히 거의 5:5로 아름답게 나누어져있다.
이제 한글을 제외한 나머지는 빈칸으로 바꿔주고 빈칸을 null로 바꾼다음 null값을 제거해버리자.
순수하게 한글만 남기도록 전처리한다.
train[‘발화’] = train[‘발화’].str.replace(“[^ㄱ-ㅎㅏ-ㅣ가-힣 ]”,””) test[‘발화’] = test[‘발화’].str.replace(“[^ㄱ-ㅎㅏ-ㅣ가-힣 ]”,””) train[‘발화’] = train[‘발화’].str.replace(‘^ +’, “”) test[‘발화’] = test[‘발화’].str.replace(‘^ +’, “”) train[‘발화’].replace(”, np.nan, inplace = True) test[‘발화’].replace(”, np.nan, inplace = True)
이 과정을 하였더니 train에서 1520개, test에서 166개가 제거 되었다.
stopwords = [‘도’, ‘는’, ‘다’, ‘의’, ‘가’, ‘이’, ‘은’, ‘한’, ‘에’, ‘하’, ‘고’, ‘을’, ‘를’, ‘인’, ‘듯’, ‘과’, ‘와’, ‘네’, ‘들’, ‘듯’, ‘지’, ‘임’, ‘게’] okt = Okt()
stopwords는 참 어렵다. 너무 빡빡하게 설정할 경우 단어들이 다 끊겨버리고 너무 느슨하게 해도 이상하게 분류가 된다.
우리는 다른 블로그들을 참고하면서 간단하게 설정하였다.
t_train = [] t_test = [] for sentence in train[‘발화’]: temp_X = okt.morphs(sentence, stem = True) temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거 t_train.append(temp_X) for sentence in test[‘발화’]: temp_X = okt.morphs(sentence, stem = True) # 토큰화 temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거 t_test.append(temp_X)
문장을 단어단위로 쪼개어 리스트에 넣어주는 작업.
1시간 조금 안되게 돌아갔다.
tokenizer = Tokenizer() tokenizer.fit_on_texts(t_train) tokenizer.fit_on_texts(t_test)
쪼개진 단어들에 숫자를 붙여주었다. 딥러닝을 위한 단계!
근데 매번 껐다켰다할때마다 이 사전을 다시 만드는 작업이 너무나도 힘들었다.
그런데 pickle이라는 함수가 객체를 저장할 수 있게 해준다고 한다. 나이쓰
import pickle ## Save pickle with open(“movieshopping.pickle”,”wb”) as fw: pickle.dump(tokenizer, fw)
1시간 조금 안되게 걸려 만든 단어사전을 저장해주었다.
threshold = 1 total_cnt = len(tokenizer.word_index) # 단어의 수 rare_cnt = 0 # 등장 빈도수가 threshold보다 작은 단어의 개수를 카운트 total_freq = 0 # 훈련 데이터의 전체 단어 빈도수 총 합 rare_freq = 0 # 등장 빈도수가 threshold보다 작은 단어의 등장 빈도수의 총 합 # 단어와 빈도수의 쌍(pair)을 key와 value로 받는다. for key, value in tokenizer.word_counts.items(): total_freq = total_freq + value # 단어의 등장 빈도수가 threshold보다 작으면 if(value < threshold): rare_cnt = rare_cnt + 1 rare_freq = rare_freq + value print('단어 집합(vocabulary)의 크기 :',total_cnt) print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt)) print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt) * 100) print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq) * 100) 단어 집합(vocabulary)의 크기 : 75397 등장 빈도가 0번 이하인 희귀 단어의 수: 0 단어 집합에서 희귀 단어의 비율: 0.0 전체 등장 빈도에서 희귀 단어 등장 빈도 비율: 0.0 단어의 종류만 75397개... 여기서 2번 이하로 등장한 단어가 전체 단어에서 46% 3번 이하는 56%.. 과감하게 전부다 학습에 사용하기로 하였다. 또한, 한두번 나온 단어가 그 문장의 감성을 표현할 수 있는 핵심단어일 수도 있다는 생각도 하였기 때문에 적게 나온 단어를 따로 제거하지 않았다. t_train1 = tokenizer.texts_to_sequences(t_train) t_test1 = tokenizer.texts_to_sequences(t_test) 단어로 쪼개진 문장을 숫자로 바꿔주었다. e_train = train['감정_int'] e_test = test['감정_int'] 정답데이터로 사용할 감정_int도 분류! print('문장의 최대 길이 :',max(len(l) for l in t_train1)) print('문장의 평균 길이 :',sum(map(len, t_train1))/len(t_train1)) plt.hist([len(s) for s in t_train1], bins=50) plt.xlabel('length of samples') plt.ylabel('number of samples') plt.show() 데이터셋에서 문장의 최대 길이(단어의 수) = 69 평균길이는 11.46 분포도 그래프로 보여주었다. def below_threshold_len(max_len, nested_list): cnt = 0 for s in nested_list: if(len(s) <= max_len): cnt = cnt + 1 print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s'%(max_len, (cnt / len(nested_list))*100)) max_len = 42 below_threshold_len(max_len, t_train1) 전체 샘플 중 길이가 42 이하인 샘플의 비율: 99.18666321712696 길이를 길게 잡을 경우 학습에 시간이 오래걸리기 때문에 가장 데이터손실이 적으면서도 학습시간을 줄일 수 있도록 전체의 99.18%를 포함하도록 문장길이를 42로 설정하였다. t_train2 = pad_sequences(t_train1, maxlen = max_len) t_test2 = pad_sequences(t_test1, maxlen = max_len) 문장길이를 모두 42로 패딩하였다. from keras import models from tensorflow.keras.layers import Embedding, Dense, LSTM, GRU, Dropout from tensorflow.keras.models import Sequential from tensorflow.keras.models import load_model from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint 딥러닝에 사용할 모듈들 model = Sequential() model.add(Embedding(vocab_size, 100)) model.add(LSTM(128, return_sequences = True)) model.add(Dropout(0.5)) model.add(GRU(128)) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) model.summary() es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4) mc = ModelCheckpoint('bilstm.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True) model.compile(optimizer='adam', loss='mse', metrics=['acc']) history = model.fit(t_train2, e_train, epochs=15, callbacks=[es, mc], batch_size=6000, validation_split=0.2) optimizer, loss, layer들을 상당히 많이 바꿔가면서 진행하였다. 그 결과 대부분 잘 나왔지만 optimizer = 'adam', loss='mse'가 대체적으로 결과가 좋았고 LSTM과 GRU를 섞은 것이 결과도 가장 좋았다. layer를 많이 쌓는다고 무조건 좋지 않았고 오히려 안좋았다. loaded_model = load_model('bilstm.h5') print(" 테스트 정확도: %.4f" % (loaded_model.evaluate(t_test2, e_test)[1])) bilstm도 돌리다가 모델저장파일명을 안바꿨지만.. 어쨌든 ... 모델 Train loss Train accuracy val loss val accuracy LSTM 0.0918 0.879 0.1003 0.8644 GRU 0.0886 0.884 0.1014 0.8639 GRU (optimizer : rmsprop) 0.2165 0.9204 0.2538 0.9030 BiLSTM 0.0683 0.9159 0.084 0.8912 LSTM + GRU 0.0678 0.9163 0.0824 0.8912 GRU+LSTM+BiLSTM 0.0645 0.9197 0.0833 0.8926 LSTM + Dropout + GRU + Dropout 0.0654 0.9208 0.0840 0.8899 이러한 결과를 보여주었다. 어쨌든.. 위에서 저장한 피클데이터, 모델파일을 통해 추천시스템을 만들었다. 솔직히 다이나믹한 추천시스템은 시간부족으로 만들지 못했다. 그냥 리스트에 다양한 항목을 넣고 감정점수에 따라서 아이템을 추천하는 방식으로 만들어보았다. from tensorflow.keras.models import load_model import random from konlpy.tag import Okt import os from tensorflow.keras.preprocessing.text import Tokenizer import pickle from tensorflow.keras.preprocessing.sequence import pad_sequences with open("finalsenti.pickle","rb") as fr: tokenizer = pickle.load(fr) okt = Okt() stopwords = ['도', '는', '다', '의', '가', '이', '은', '한', '에', '하', '고', '을', '를', '인', '듯', '과', '와', '네', '들', '듯', '지', '임', '게'] loaded_model = load_model('final.h5') max_len = 42 global corpus global avg_emo global score corpus = [] avg_emo = 0 heal = ['여수 밤바다', '파주 평화누리공원', '순천 갈대밭', '제주도 영실코스', '진주 진양호', '장흥유원지', '대구 앞산정만대', '춘천 해피초원농장' ,' 속초 해수욕장', '경주 불국사', '포항 호미곶', '남해 두모마을', '대관령 하늘목장', '군산 철길마을', '국립 광릉수목원', '금선사 템플스테이', '보성 제암산자연휴양림','군산 선유도'] extreme= ['통영 어드벤처 타워', '제주도 스쿠버다이빙', '단양 패러글라이딩', '강원 내린천 래프팅', '충주 스카이다이빙', '하남 스포츠몬스터', '서울 한강 워터 제트팩', '일산 인공 서핑', '영월 동강래프팅', '여수 스카이플라이', '문경 패러글라이딩', '경남 하동 하동알프스레포츠', '인천 스카이 짚라인', '강화 루지'] movie=['루카','콰이어트 플레이스','크루엘라','컨저링 3:악마가 시켰다','여고괴담 여섯번째 이야기','분노의 질주: 더 얼티메이트','캐시트럭', '클라이밍', '그 여름, 가장 차가웠던', '폭력의 그림자', '청춘 선거', '그레타 툰베리', '낫아웃', '마세티 킬즈', '프로페서 앤 매드맨', '화이트 온 화이트', '아야와 마녀', '까치발', '플래시백', '애플', '혼자 사는 사람들', '강호아녀', '파이프라인', '분노의 질주'] #음악 (네이버 바이브 참고 1위~20위) k_balad=['Timeless-SG워너비', '추적이는 여름 비가 되어-장범준', '밤하늘의 별을 (2020)-경서', '어떻게 이별까지 사랑하겠어, 널 사랑하는 거지-AKMU (악동뮤지션)', '내 입술 따뜻한 커피처럼-청하 Colde(콜드)', '서울의 잠 못 이루는 밤 (Feat. 이수현)-10CM', '잠이 오질 않네요-장범준', 'I Love U-성시경', '내사람 (Partner For Life)-SG워너비', '취기를 빌려-산들', '안녕 (Hello)-조이', '밤편지-아이유(IU)', 'Anti-Romantic-투모로우바이투게더', '너의 모든 순간-성시경', '좋을텐데 (If Only) (Feat. 폴킴)-조이', '봄 안녕 봄-아이유(IU)', 'Love poem -아이유(IU)', '아이와 나의 바다-아이유(IU)', '벌써 일년-반하나& MJ(써니사이드)', '이렇게 좋아해 본 적이 없어요 -CHEEZE (치즈)' ] k_dance=[ 'Butter-방탄소년단', 'Next Level-aespa', 'Dun Dun Dance-오마이걸(OH MY GIRL)', '치맛바람 (Chi Mat Ba Ram)-브레이브걸스(Brave Girls)', 'Alcohol-Free-TWICE(트와이스)', "롤린 (Rollin')-브레이브걸스(Brave Girls)", '라일락-아이유(IU)', 'ASAP-STAYC(스테이씨)', 'Dynamite-방탄소년단', '상상더하기-MSG워너비', 'Celebrity-아이유(IU)', '상상더하기-라붐(LABOUM)', 'Ready to love-세븐틴', 'Dolphin-오마이걸(OH MY GIRL)', 'Lovesick Girls-BLACKPINK', 'Pool Party (Feat. 이찬 of DKB)-브레이브걸스(Brave Girls)', "Heaven's Cloud-세븐틴", '체념-정상동기(김정수, 정기석, 이동휘, 이상이)', '어푸 (Ah puh)-아이유(IU)', ] k_hip=[ '마.피.아. In the morning-ITZY(있지)', '봄날-방탄소년단', 'Life Goes On-방탄소년단', '맛 (Hot Sauce)-NCT DREAM', '밸런스 게임-투모로우바이투게더', 'GAM3 BO1-세븐틴', '비도 오고 그래서 (Feat. 신용재)-헤이즈 (Heize)', 'METEOR-창모(CHANGMO)', 'DNA-방탄소년단', 'IDOL-방탄소년단', 'FAKE LOVE-방탄소년단', '피 땀 눈물-방탄소년단', '사이렌-호미들', '멜로디-ASH ISLAND', 'I NEED U-방탄소년단', '아무노래-지코 (ZICO)', '어떻게 지내 (Prod. By VAN.C)-오반(OVAN)', 'Rainy day (Feat. ASH ISLAND, Skinny Brown)-PATEKO(파테코)', '뚜두뚜두 (DDU-DU DDU-DU)-BLACKPINK'] trt=[ '이제 나만 믿어요-임영웅', '별빛 같은 나의 사랑아-임영웅', '다시 사랑한다면 (김필 Ver.)-임영웅', 'HERO-임영웅', '미워요-임영웅', '잊어야 한다는 마음으로-임영웅', '계단말고 엘리베이터-임영웅', '소나기-임영웅', '바보같지만-임영웅', '따라따라-임영웅', '당신-임영웅', '내 마음 별과 같이-임영웅', '고맙소-김호중', '만개 (Prod. 신지후)-김호중', '나보다 더 사랑해요-김호중', '애인이 되어줄게요 (Prod. 알고보니, 혼수상태)-김호중', '퇴근길-김호중', '할무니-김호중', '우산이 없어요-김호중', '천년의 사랑-김호중' ] f_dance=[ 'You-Regard, Troye Sivan, Tate McRae', 'Closer (Feat. Halsey)-The Chainsmokers', 'Faded-Alan Walker', 'One Kiss-Calvin Harris, Dua Lipa', 'Heartbreak Anthem-Galantis, David Guetta, Little Mix', 'Something Just Like This-The Chainsmokers, Coldplay', 'This Is What You Came For (Feat. Rihanna)-Calvin Harris', 'The Middle-Zedd, Grey, Maren Morris', 'Symphony (Feat. Zara Larsson)-Clean Bandit', 'Wake Me Up-Avicii', 'Waste It On Me (Feat. BTS(방탄소년단))-Steve Aoki', 'How To Love (Feat. Sofia Reyes)-Cash Cash', 'Bad Boy (with Wiz Khalifa, bbno$, MAX)-Yung Bae, Wiz Khalifa, bbno$, MAX', 'Titans (Feat. Sia & Labrinth) (Imanbek Remix)-Major Lazer', 'Feels (Feat. Pharrell Williams, Katy Perry, Big Sean)-Calvin Harris', 'Rise (Feat. Jack & Jack)-Jonas Blue', 'Mama (Feat. William Singe)-Jonas Blue', 'Just Got Paid (Feat. French Montana)-Sigala, Ella Eyre, Meghan Trainor', 'Love Line-Shift K3y, Tinashe', 'Lonely Together (Feat. Rita Ora)-Avicii' ] newage=[ 'River Flows In You-이루마', 'Letter From The Earth (지구에서 온 편지)-김광민', '익숙한 그 집 앞-유희열', '처음부터 지금까지 (Inst.)-박정원', '냉정과 열정 사이 OST (冷靜と情熱のあいだ)-Ryo Yoshimata', '''Tomorrow's Promise-Kevin Kern''', "Mia & Sebastian's Theme-Justin Hurwitz", 'Recuerods de la Alhambra (알함브라 궁전의 추억)-Claude Ciari', '''Gabriel's Oboe-Ennio Morricone''', 'Rain-Ryuichi Sakamoto', 'Romance-Yuhki Kuramoto', 'Second Romance-Yuhki Kuramoto', 'Crystal Rainbow-데이드림(Daydream)', 'My Road (Live)-Lee Oskar', 'Last Carnival-Acoustic Cafe', 'Return To The Heart-David Lanz', 'Adagio-Secret Garden', 'Loving You-Kenny G' ] korean = ["삼계탕", "삼겹살", "곱창", "찜닭", "오리고기", "소고기", "국밥", "닭도리탕", "낙곱새", "라면", "비빔밥", "칼국수", "수제비", "갈비", "제육볶음"] western = ["스테이크", "파스타", "필라프", "감바스", "리조또", "샐러드", "피자", "빠에야", "플래터", "스튜"] asian = ["짜장면", "뿌팟퐁커리", "팟타이", "나시고랭", "쌀국수", "미고랭", "카레", "마라탕", "마라샹궈", "훠궈", "돈까스", "월남쌈", "라멘", "탄탄멘", "규동", "꿔바로우", "똠양꿍", "물냉면"] spicy = ["떡볶이", "김치찜", "김치찌개", "감자탕", "짬뽕", "닭발", "부대찌개", "순두부찌개", "아구찜", "해물찜", "육개장", "낙지볶음", "쭈꾸미", "돼지갈비찜", "소꼬리찜", "비빔냉면"] dessert = ["와플", "마카롱", "빙수", "크로크모슈", "케이크", "허니바게트볼", "머쉬룸수프볼", "에그데니쉬", "케이크", "치아바타", "호두파운드케이크", "쿠키", "허니브레드", "오믈렛", "베이글"] snack = ["닭강정", "양꼬치", "핫윙", "소떡소떡", "가라아게", "콘치즈", "감자튀김", "치킨너겟", "치킨", "낫쵸", "소시지", "버터구이", "계란찜", "핫도그", "해쉬브라운"] coffee = ["아메리카노", "콜드브루", "바닐라 라떼", "카페 라떼", "카라멜 마키아또", "카페 모카", "바닐라 프라페", "카페모카 프라페", "연유 라떼", "화이트 모카", "민트 모카", "헤이즐넛 라떼", "에스프레소", "오곡 프라페", "쿠앤크 프라페"] beverage = ["초코 라떼", "민트초코 라떼", "밀크티", "흑당 버블티", "레몬차", "자몽차", "유자차", "모히토", "요거트 스무디", "블루베리 스무디", "딸기 스무디", "애플망고 스무디", "레몬 에이드", "자몽 에이드", "생과일 주스"] motivation = ["자신을 믿어라. 자신의 능력을 신뢰하라. 겸손하지만 합리적인 자신감 없이는 성공할 수도 행복할 수도 없다. - 노먼 빈센트 필", "조금 더 많이 인내하자. 조금 더 많이 노력하자. 그러면 절망적 실패로 보였던 것이 빛나는 성공으로 변할 수 있다. - 알버트 휴버드", "당신이 인생의 주인공이기 때문이다. 그 사실을 잊지말라. 지금까지 당신이 만들어온 의식적 그리고 무의식적 선택으로 인해 지금의 당신이 있는것이다. - 바바라 홀", "먹는 칼로리보다 에너지 소모가 적으면 살이 찌듯이, 걱정만 하고 행동하지 않으면 걱정이 찐다.", "이미 끝나버린 일을 후회하기 보다는 하고 싶었던 일을 하지 못한 것을 후회하라 - 탈무드", "기회가 주어지면 최선을 다하는 것이 아니라 최선을 다하고 있으면 기회가 주어지는 것이다 - 신영준", "낭비한 시간에 대한 후회는 더 큰 시간 낭비이다 - 메이슨 쿨리", "성공은 매일 부단하게 반복된 작은 노력의 합산이다.", "현명한 사람은 앉아서 손해 본 것을 한탄만 하지 않고 즐겁게 그 손해를 회복할 방법을 찾는다. - 셰익스피어", "고통을 주지 않는것은 쾌락도 주지 않는다 - 몽테뉴", "시간은 간다", "살아가는 사람들 중 대부분은 자신에게 올 기회를 기다리나 기회라는 것은 기다리는 사람에게는 쉽게 오지 않는 법이다", "기회를 얻을 수 있게 기다리는 사람이 되기보다는 기회를 얻을 수 있는 실력을 먼저 쌓아야 한다. 자신이 하는 일에 열중하고 노력하다보면 자연스럽게 기회는 찾아온다.", "변화를 위해서 가장 중요한 것은 행동하는 첫걸음이다.", "무엇이든 하루아침에 만들어지는 것은 없다. 로마 또한 하루아침에 만들어지지 않았다. 이 말은 무언가를 만들기 위해서는 그것을 만들기 위해 노력하고 집중 해야 한다는 것이다.", "스스로를 믿고 자신이 가지고 있는 능력을 신뢰해야 한다. 하지만 거만하게 행동하지 말고 겸손해라. 성공을 위해서 자신감이 필요하지만 오만함은 필요하지 않다.", "끝난 일은 언급할 필요가 없으며 지난 일은 허물을 물을 필요가 없다. - 공자", "어렵고 힘든 상황일수록 서두르지 말고 침착해라. 성급하게 하는 행동에는 실수가 포함되기 쉽다.", "나의 하루를 설명할 수 있는 사람이 곁에 있다는 건 생각보다 기분 좋은 일이야 그러니 너도 생각보다 좋은 사람이지 - 흔글", "잠 못 자고 있지, 얼른 자, 걱정하는 일 안 생겨 좋은 일은 아니더라도 아무 일 없을 거야 혼자 있는 새벽을 걱정으로 보내지는 마 - 흔글", "봄바람도 살랑살랑 불고 꽃도 예쁘게 피어있으니 얼마나 놀고 싶겠냐만은, 그래도 그 시간들을 이겨내면 너의 인생에 꽃이 필 테니 조금만 참고 바람을 이겨내기를 - 흔글"] category = [heal,extreme,movie,k_balad,k_dance,k_hip,trt,f_dance,newage,korean,western,asian,spicy,dessert,snack,coffee,beverage] f8 = [extreme,movie,k_balad,k_dance,k_hip,trt,f_dance,korean,western,asian,spicy,dessert,snack,coffee,beverage] f6 = [extreme,movie,k_balad,k_dance,k_hip,trt,f_dance,korean,western,asian,spicy,dessert,snack,coffee,beverage] f3 = [heal,extreme,movie,k_balad,k_dance,k_hip,trt,f_dance,newage,korean,western,asian,spicy,dessert,snack,coffee,beverage, dessert] f1 = [heal,movie,k_balad,k_dance,k_hip,trt,f_dance,newage,korean,western,asian,spicy,dessert,snack,coffee,beverage, dessert] f0 = [heal,movie,k_balad,k_dance,k_hip,f_dance,newage,korean,western,asian,spicy,spicy,dessert,snack,snack,coffee,beverage] def recomend_sys(new_sentence): global score global timecheck global corpus global score global avg_emo new_sentence = okt.morphs(new_sentence, stem=True) # 토큰화 new_sentence = [word for word in new_sentence if not word in stopwords] # 불용어 제거 encoded = tokenizer.texts_to_sequences([new_sentence]) # 정수 인코딩 pad_new = pad_sequences(encoded, maxlen = max_len) # 패딩 score = float(loaded_model.predict(pad_new)) # 예측 corpus.append(score) if len(corpus) >= 5: avg_emo = sum(corpus)/len(corpus) if(avg_emo > 0.8): pick = random.choice(f8) if pick == motivation: # | pick == rest: print(“기분 점수 : {0:.2f}”.format(avg_emo*100)) print(“당신을 위한 한마디 : {1}
“.format(random.choice(pick))) corpus=[] else: print(“기분 점수 : {0:.2f}”.format(avg_emo*100)) print(“오늘처럼 좋은 날엔 {0} 어떠신가요?
“.format(random.choice(pick))) corpus=[] elif(avg_emo > 0.6): pick = random.choice(f6) if pick == motivation: # | pick == rest: print(“기분 점수 : {0:.2f}”.format(avg_emo*100)) print(“당신을 위한 한마디 : {1}
“.format(random.choice(pick))) corpus=[] else: print(“기분 점수 : {0:.2f}”.format(avg_emo*100)) print(“좋은 일있으신가요? 오늘 {0} 어떠세요?
“.format(random.choice(pick))) corpus=[] elif(avg_emo > 0.4) : pick = random.choice(category) if pick == motivation: # | pick == rest: print(“기분 점수 : {0:.2f}”.format(avg_emo*100)) print(“당신을 위한 한마디 : {1}
“.format(random.choice(pick))) corpus=[] else: print(“기분 점수 : {0:.2f}”.format(avg_emo*100)) print(“오늘같은 날에는 {0} 어때요? 기분이 좋아질거에요!!
“.format(random.choice(pick))) corpus=[] elif(avg_emo > 0.3) : pick = random.choice(f3) if pick == motivation: # | pick == rest: print(“기분 점수 : {0:.2f}”.format(avg_emo*100)) print(“당신을 위한 한마디 : {1}
“.format(random.choice(pick))) corpus=[] else: print(“기분 점수 : {0:.2f}”.format(avg_emo*100)) print(“꿀꿀한 오늘 {0} 추천해요.
“.format(random.choice(pick))) corpus=[] elif(avg_emo > 0.18) : pick = random.choice(f1) if pick == motivation: # | pick == rest: print(“기분 점수 : {0:.2f}”.format(avg_emo*100)) print(“당신을 위한 한마디 : {1}
“.format(random.choice(pick))) corpus=[] else: print(“기분 점수 : {0:.2f}”.format(avg_emo*100)) print(“오늘 {0} 어떠세요? 안좋은 기분을 환기시켜줄 거에요.
“.format(random.choice(pick))) corpus=[] else: pick = random.choice(f0) if pick == motivation: # | pick == rest: print(“기분 점수 : {0:.2f}”.format(avg_emo*100)) print(“당신을 위한 한마디 : {1}
“.format(random.choice(pick))) corpus=[] else: print(“기분 점수 : {0:.2f}”.format(avg_emo*100)) print(“오늘 안좋은 일이 있으셨나요. 오늘같은 날 {0} 어떠세요?
“.format(random.choice(pick))) corpus=[] else: print(‘감정 분석까지 {0}개의 문장이 남았어요!’.format(5-len(corpus)))
5개의 문장이 들어갔을 때, 평균점수로 추천하도록 만들었다.
구현되는 모습을 동영상으로 촬영하였다.
이상…기타 프론트엔드로 이쁘게 구현하거나 좀더 멋드러지게 만들지는 못했지만 NLP를 직접 분석하고 RNN에 대해서 많은 공부를 할 수 있었던 값지고 소중한 경험이었다.
감정기반 추천서비스.(케미) 5조.7z 7.61MB
최종 발표 ppt를 참고하면 이해하는데 도움이 될 것 같다.
728×90
LIST
키워드에 대한 정보 파이썬 감성 분석
다음은 Bing에서 파이썬 감성 분석 주제에 대한 검색 결과입니다. 필요한 경우 더 읽을 수 있습니다.
이 기사는 인터넷의 다양한 출처에서 편집되었습니다. 이 기사가 유용했기를 바랍니다. 이 기사가 유용하다고 생각되면 공유하십시오. 매우 감사합니다!
사람들이 주제에 대해 자주 검색하는 키워드 이것이 데이터 분석이다 (파이썬 편) – 17. 4장 감성 분석이란
- 파이썬 강의
- 파이썬
- python
- 데이터분석
- datascience
- data analysis
- pandas
- numpy
- matplotlib
- sklearn
- 회귀분석
- 예측분석
- 이것이데이터분석이다
- 한빛미디어
- 윤기태
이것이 #데이터 #분석이다 #(파이썬 #편) #- #17. #4장 #감성 #분석이란
YouTube에서 파이썬 감성 분석 주제의 다른 동영상 보기
주제에 대한 기사를 시청해 주셔서 감사합니다 이것이 데이터 분석이다 (파이썬 편) – 17. 4장 감성 분석이란 | 파이썬 감성 분석, 이 기사가 유용하다고 생각되면 공유하십시오, 매우 감사합니다.